2021. 1. 22. 20:54ㆍ빅데이터 플랫폼 (Bigdata Platforms)/아파치 카프카 (Apache Kafka)
시작하면서
카프카를 설치하기에 앞서, 이전에 카프카에 대해 소개했던 글을 먼저 읽으시길 바랍니다.
그리고 카프카를 설치하는 방법은 공식 사이트에서 잘 소개되어 있습니다.
위 글을 따라서 진행해도 크게 무리는 없으나 어디까지나 가장 기초적인 수준이고, 이전에 주키퍼 클러스터를 구축했으므로 카프카와 주키퍼를 연동하여 클러스터를 만드는 것까지 소개하겠습니다.
설계하기
우선 장치 dim, oim, jim 3개를 가지고 어떻게 브로커 서버를 구성할 지 생각해봅니다.

지금은 각 필드명이 무슨 의미인지 알 필요는 없습니다.
다만 이전에 만든 주키퍼 클러스터에 대한 정보를 가져와야 되고, broker.id를 각 서버가 고유하게 가진다는 점을 주목합니다. 나머지 포트 및 프로토콜에 대해서는 아래 'server.properties 설정하기' 글에서 설명해드리겠습니다.
카프카 다운로드하기
카프카 설치 파일은 여기를 방문하면 받을 수 있습니다.
Binary downloads에서 저는 Scala 2.12 버전에 해당하는 카프카 2.7.0 버전을 다운로드했습니다.
다운로드가 완료되면, 압축을 풀고 /usr/local/kafka 에 디렉터리 내 모든 파일이 위치할 수 있도록 해주세요.
~$ cd Downloads/
~/Downloads$ tar -xf kafka_2.12-2.7.0.tgz
~/Downloads$ mv kafka_2.12-2.7.0 kafka
~/Downloads$ sudo mv kafka /usr/local/
[sudo] denny의 암호:
~/Downloads$ cd /usr/local/kafka/
/usr/local/kafka$ ls
LICENSE NOTICE bin config libs site-docs환경 변수 등록하기
환경 변수를 등록하기 위해서 홈 디렉터리에 위치한 .bashrc를 엽니다.
~$ gedit .bashrc
맨 밑에 다음 내용을 추가합니다.
export KAFKA_HOME=/usr/local/kafka
export PATH=$PATH:$KAFKA_HOME/bin
이제 마지막으로 환경 변수들을 갱신하면 됩니다.
~$ source .bashrc카프카 설정하기
카프카 내부 디렉터리에서 config/server.properties 파일을 보면 서버 구현에 필요한 기본적인 속성들을 볼 수 있습니다. 또한 각각 키-값 형식의 속성 파일 형식로 정의되어 있음을 알 수 있죠.
...
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=0
...
서버를 포함해 카프카는 총 7가지로 설정할 수 있습니다.
- 브로커(서버)
- 토픽
- 프로듀서
- 컨슈머
- 카프카 연결
- 카프카 스트림
- 관리자
실제로 관련 사이트를 방문해보면 스크롤 하는 것도 시간이 꽤 걸릴만큼 내용이 어마무시하게 많습니다.
하지만 이번 포스팅에서는 server.propertise 파일에 있는 설정값만 유심히 다루는 것으로 하겠습니다.
server.properties 설정하기
이전에 브로커(broker)에 대해 설명한 적이 있습니다. 용어의 혼동을 줄이기 위해 여기서는 broker를 서버(server)라고 표현하겠습니다.
카프카는 분산 환경에서 동작하도록 서버를 여러 개 만들 수 있습니다. 당연히 서버를 추가하거나 삭제함으로 시스템 상에서 유연성(elasticity)을 가지는 것은 카프카의 장점 중 하나입니다.
이때 각 서버는 고유의 server.properties 파일로 실행되기 때문에 앞서 설계한 대로 여러 개의 서버를 구분하여 설정한 결과를 소개하도록 하겠습니다.
| 속성 이름 | 서버 0 | 서버 1 | 서버 2 | 서버 3 |
|---|---|---|---|---|
| broker.id | 1 | 2 | 3 | 4 |
| 각 서버들이 가지는 고유한 아이디입니다. | ||||
| zookeeper.connect | dim:2181,oim:2181,jim:2181 | |||
| 주키퍼 클러스터와 연결하기 위해 호스트 주소를 작성합니다. | ||||
| zookeeper.connection.timeout.ms | 10000 | |||
| ms 단위로, 주키퍼와 연결 시 timeout 시간입니다. | ||||
| num.network.threads | 3 (기본값) | |||
| 클라이언트로부터 요청을 받거나 응답을 보낼 때 사용할 스레드(thread) 수 입니다. | ||||
| log.dirs | /usr/local/kafka/logs0 | /usr/local/kafka/logs1 | /usr/local/kafka/logs2 | /usr/local/kafka/logs3 |
| 로그(log) 데이터가 저장될 장소입니다. | ||||
| num.io.threads | 8 (기본값) | |||
| 메시지를 처리할 때 사용할 스레드(thread) 수 입니다. (디스크 I/O 포함) | ||||
| socket.send.buffer.bytes | 102400 (기본값) | |||
| byte 단위로, 소켓 통신에서 데이터를 보낼 때 사용할 버퍼 크기입니다. | ||||
| socket.receive.buffer.bytes | 102400 (기본값) | |||
| byte 단위로, 소켓 통신에서 데이터를 받을 때 사용할 버퍼 크기입니다. | ||||
| socket.request.max.bytes | 104857600 (기본값) | |||
| byte 단위로, 소켓 통신에서 데이터를 받을 때 데이터의 크기를 제한입니다. | ||||
| num.partitions | 1 (기본값) | |||
| 토픽 당 로그 파티션 수를 말합니다. 현재 굳이 파티션을 나눌 필요가 없어 1로 두었습니다. | ||||
| num.recovery.threads.per.data.dir | 1 (기본값) | |||
| 로그 복구에 사용되는 스레드 수입니다. 이또한 기본값으로 두었습니다. | ||||
| group.initial.rebalance.delay.ms | 3000 (기본값) | |||
| 컨슈머가 추가되거나 삭제되었을 때 리밸런싱(rebalancing)하기 전 지연시간입니다. 해당 부분은 다음 포스팅에서 설명하겠습니다. | ||||
바인딩은 어떻게 이루어지나요?
이미 이전에 각 서버들은 동일하게 복제된 데이터베이스를 가진다고 설명했습니다. 이때 원본 데이터베이스에 데이터를 쓰는 서버는 1개여야 합니다.(너무 당연하죠) 이때 원본 데이터베이스에 접근하는 서버를 리더(leader)라고 표현했을 때, 클라이언트는 리더의 존재에 대해 알아야합니다.
따라서 카프카는 퍼블리싱하거나 컨슘을 하려는 외부에 있는 클라이언트(client)에게 리더에 대한 정보를 줄 수 있도록 해야하고, 때문에 어떻게든 최초 접속이 이루어져야 합니다. 그리고 접속이 된 주소로부터 데이터 교환이 이루어져야되죠.
The key thing is that when you run a client, the broker you pass to it is just where it’s going to go and get the metadata about brokers in the cluster from. The actual host and IP that it will connect to for reading/writing data is based on the data that the broker passes back in that initial connection—even if it’s just a single node and the broker returned is the same as the one it’s connected to.
따라서 이를 위해 각 서버는, IP 주소와 포트 번호, 프로토콜(protocol)을 조합하여 클라이언트에게 알려줄 주소를 2가지로 만듭니다. 그리고 바인딩(binding)을 함으로써, 중복된 주소가 아님을 확인하고 네트워크 서비스를 가능하게 하여 다른 클라이언트가 접속할 수 있도록 합니다.
confluent사의 글을 참고하면 더 이해가 쉽습니다.
| 속성 이름 | 서버 0 | 서버 1 | 서버 2 | 서버 3 |
|---|---|---|---|---|
| listeners | INTERNAL://dim:19090,EXTERNAL://dim:29090 | INTERNAL://dim:19091,EXTERNAL://dim:29091 | INTERNAL://oim:19090,EXTERNAL://oim:29090 | INTERNAL://jim:19090,EXTERNAL://jim:29090 |
| 지속적으로 클라이언트와 소켓 통신을 할 주소입니다. 자세한 규칙은 여기를 참조해주세요. | ||||
| advertised.listeners | INTERNAL://dim:19090,EXTERNAL://dim:29090 | INTERNAL://dim:19091,EXTERNAL://dim:29091 | INTERNAL://oim:19090,EXTERNAL://oim:29090 | INTERNAL://jim:19090,EXTERNAL://jim:29090 |
| 외부에서 서버의 메타데이터를 얻기 위해 접속할 주소입니다. 자세한 규칙은 여기를 참조해주세요. | ||||
| listener.security.protocol.map | INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT | INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT | INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT | INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT |
| 각 프로토콜의 보안 수준을 정의합니다. 모두 PLAINTEXT로 정의했습니다. | ||||
| inter.broker.listener.name | INTERNAL | INTERNAL | INTERNAL | INTERNAL |
| 브로커끼리의 통신을 수행할 프로토콜입니다. | ||||
자, 앞서 주소를 2가지로 만든다고 했습니다. 그렇다면 왜 이렇게 나눌까요?
stackoverflow 글을 읽어보면 더욱 쉽게 이해할 수 있습니다.
listeners is what the broker will use to create server sockets.
advertised.listeners is what clients will use to connect to the brokers.
카프카는 이전에도 말했듯 여러 개의 브로커 서버를 둘 수 있습니다. 그리고 동기화를 수행하려면 서버와 통신할 수 있는 소켓(socket)이 있어야 합니다.(카프카는 TCP 소켓 통신 기반입니다) 그리고 listeners 속성은 소켓 통신을 위한 소켓 주소가 있죠.
일반적으로 advertised.listeners를 지정하지 않으면 listeners 속성값을 그대로 사용합니다. 하지만 외부 접속 경로가 도메인 주소로 정해진 것과 같이 특수한 상황에서 listeners 소켓을 0.0.0.0 (외부의 모든 인터페이스 허용)으로 만들고 advertised.listeners 를 kafka.broker.com 등으로 지정합니다. 이때 kafka.broker.com으로 접속한 프로듀서나 컨슈머 그룹은 0.0.0.0 소켓과 통신을 수행하는 것이 가능하게 되죠.
해당 내용은 추후 포스팅에서 더욱 자세하게 다루겠습니다.
프로토콜이요?
프로토콜은 데이터를 교환할 때 지켜야할 양식과 규칙이라고 생각하면 쉽습니다.

위의 이미지는 프로토콜이 왜 중요한 지 보여줍니다. 아무런 규칙 없이 상대방이 하고싶은 말을 보내면, 받는 사람의 입장에서는 어떻게 해석해야 되는 지 참 난감합니다. 따라서 몇 가지 필드명을 두어 어떤 사람이 보내도 읽을 수 있도록 하는 것이죠.
사실 프로토콜은 이 밖에도 보안성과 신속성 등 다양한 장점이 있습니다. 또한 그 종류도 여러 가지입니다. 우리가 익히 알고있는 http나 https도 프로토콜의 일종이죠.
한번 위키피디아에서 프로토콜을 검색 후 F12를 눌러서 Network 탭을 보실까요? 여기서 하나씩 눌러보면 Headers 탭에 여러 필드가 나오는 데, 대부분의 경우 공통된 필드명이 있을 것입니다. 가령 Request URL 이라던지 Request Method 처럼 말이죠.
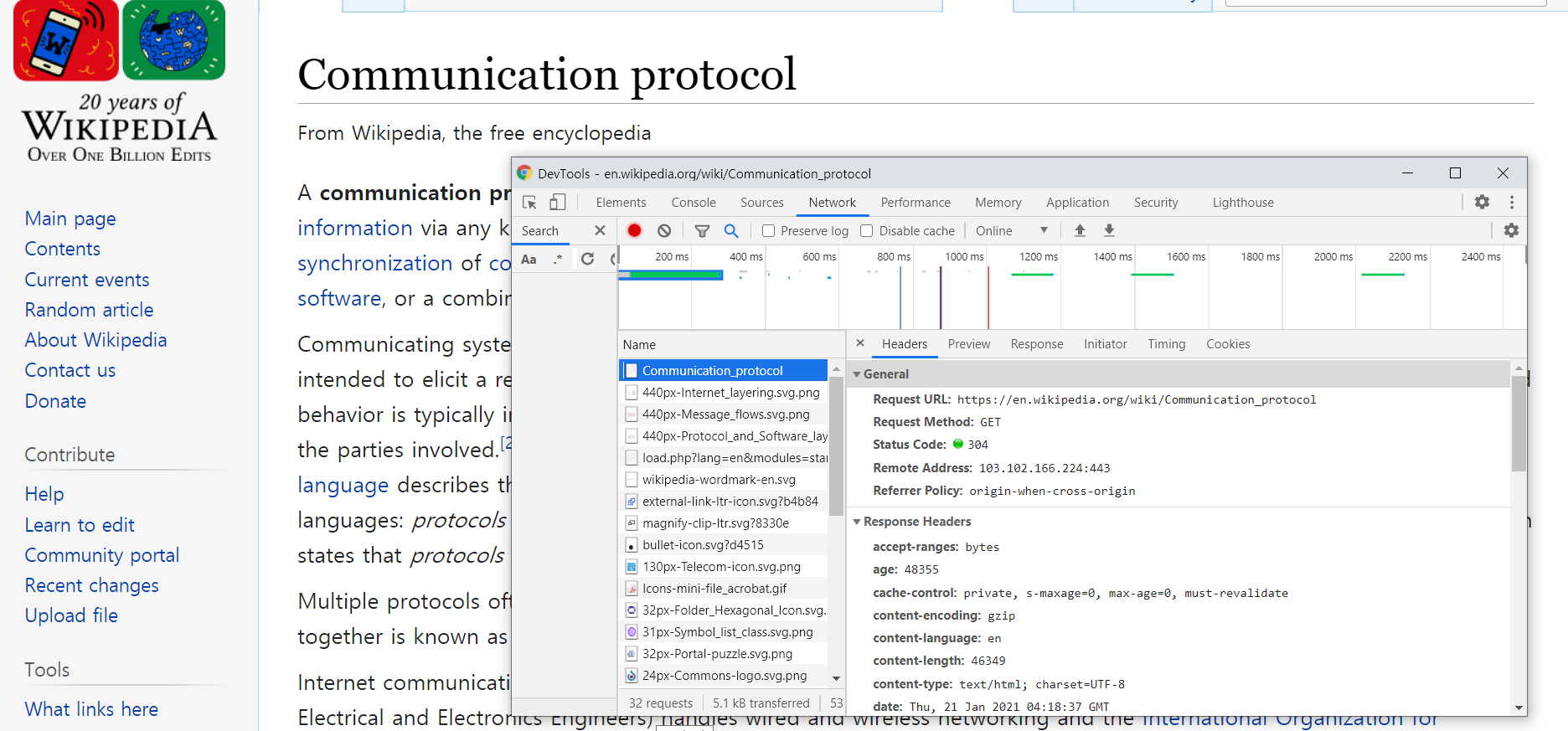
웹서버는 바로 이러한 필드명을 검색하고 값을 확인합니다.
클라이언트와 서버 간 공통된 약속을 미리 정해두었기 때문에 클라이언트가 의도한 바를 정확하게 읽을 수 있는 것이죠.
카프카는 어떤 프로토콜을 사용할까요?
listener.security.protocol.map 속성을 참고해보면 프로토콜이 우선 보안 수준에 따라 PLAINTEXT, SSL, SASL로 구분되고, 나머지는 자의적으로 생성하는 것입니다.
위에서 설계하기 챕터를 참고해보면, 각 서버에 맞춰 이미 이름과 포트번호를 정의하였고 보안은 추후 포스팅 주제로 다루기로 하도록하여 모두 PLAINTEXT 수준으로 설정하였습니다.
메시지 오프셋
클라이언트가 서버로부터 메시지를 송수신 할 때, 처리가 정상적으로 완료되었다는 알림을 받아야 합니다. 이전 글에서 카프카 메시징 모델을 설명할 때 Ack와 Offset Commit이 등장했습니다. 사실 두 방식은 서로 다르지만, 서버와의 트랜잭션 내용을 영구적으로 확정했다는 의미로써 둘 다 커밋(commit)이라고 불러도 됩니다.
자, 그렇다면 커밋은 어떻게 보낼까요?
이미 알고 있듯이 서버를 이용하는 주체는 프로듀서(producer)와 컨슈머 집단(consumer group)입니다. 카프카는 두 주체에 대해 커밋 방식을 다르게 만들었는데, 프로듀서 입장이 가장 쉬우므로 먼저 소개하겠습니다.
시작하기에 앞서 javadoc 사이트에서 소개된 예제 하나를 보여드리겠습니다.
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("transactional.id", "my-transactional-id");
Producer<String, String> producer = new KafkaProducer<>(props, new StringSerializer(), new StringSerializer());
producer.initTransactions();
try {
producer.beginTransaction();
for (int i = 0; i < 100; i++)
producer.send(new ProducerRecord<>("my-topic", Integer.toString(i), Integer.toString(i)));
producer.commitTransaction();
} catch (ProducerFencedException | OutOfOrderSequenceException | AuthorizationException e) {
producer.close();
} catch (KafkaException e) {
producer.abortTransaction();
}
producer.close();위 예제는 my-topic 이라는 토픽에 문자열 메시지 0 ~ 99를 보내고 있습니다. 아직 API 함수에 대해 깊게 설명하진 않겠지만, 가장 주목할 점은 commitTransaction 함수입니다. 사실 send 함수는 비동기적(asynchronous)으로 메시지를 로컬 버퍼에 차곡차곡 쌓아놓기 때문에 함수가 반환된다고 실질적으로 데이터를 전송하지 않습니다. 일정 주기 또는 크기가 되었을 때만 전송이 되는 것이죠.
하지만 이때 commitTransaction 함수가 호출되면 그동안 버퍼에 쌓여있던 메시지를 전송하기 시작(flush)합니다. 그리고 서버가 잘 받았는지 확인하고, 비정상일 경우 예외(exception)를 던집니다.
따라서 프로듀서는 서버의 데이터 수신이 원활이 이루어졌는 지만 판단합니다. 누가 받았고 어떻게 적재되는 지는 신경을 쓰지 않아도 되죠.
자, 이제 컨슈머 그룹을 소개할 차례입니다.
카프카는 컨슈머 그룹이 메시지를 소비(취득)할 때, 오프셋(offset)이라는 메시지 위치 정보를 이용해 관리합니다.
이때 오프셋은 다음과 같이 3가지가 존재합니다.
- Log-End-Offset(LEO) : 서버에 적재된 메시지들의 마지막 위치
- Current Offset : 컨슈머 그룹이 읽으려는 메시지들의 마지막 위치
- Commit Offset : 컨슈머 그룹이 처리했던 메시지들의 마지막 위치
더욱 쉽게 그림으로 이를 설명하도록 하겠습니다.
최초로 메시지 가져오기
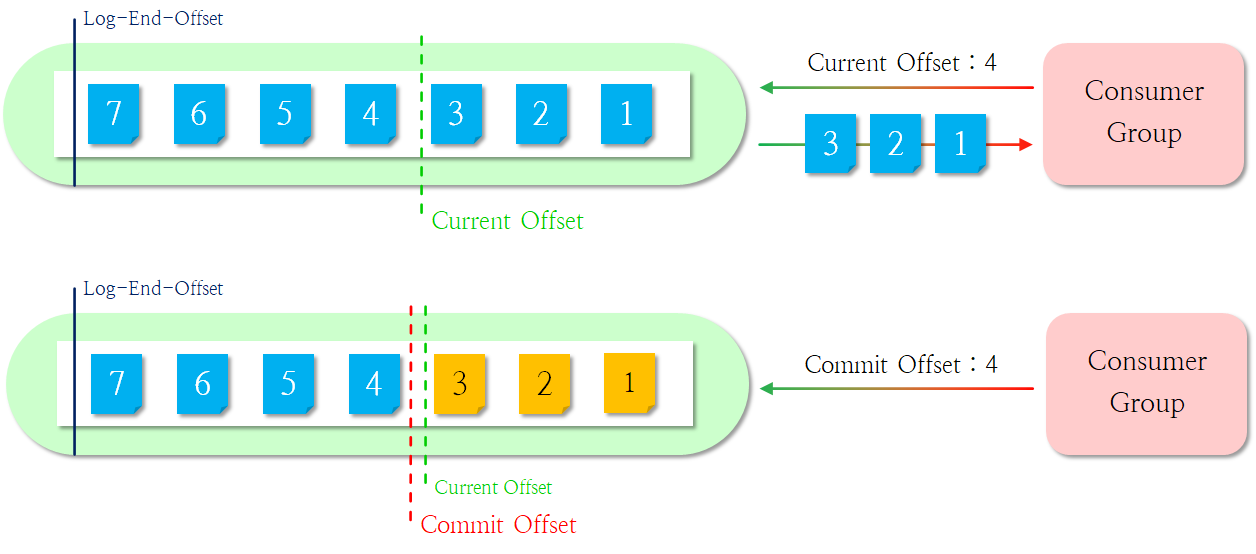
위 그림은 컨슈머 그룹(이하 그룹)이 브로커 서버(이하 서버)로부터 메시지를 최초로 읽는 상황을 보여줍니다. 처음에 그룹은 Current Offset으로 4을 전달하는데, 서버는 이를 읽고 처음 메시지부터 4번 메시지 이전까지 그룹에게 전달합니다. 이때 서버는 내부적으로 Current Offset을 4번으로 이동하는데, 이후 그룹이 메시지를 잘 처리하여 Commit Offset을 4번으로 전달하면 서버는 Commit Offset도 Current Offset이 자리한 4번으로 이동합니다. 서버는 Current Offset과 Commit Offset이 서로 동일함을 확인하고 정상 수행되었다고 판단합니다.
또 메시지 가져오기

그룹이 다시 메시지를 읽기 위해 Current Offset으로 6번을 전달합니다. 그러면 서버는 내부적으로 Current Offset을 6번으로 이동시키고, Commit Offset이 위치한 메시지인 4번부터 5번까지의 메시지를 그룹에게 전달합니다. 다시 그룹이 메시지를 잘 처리했다고 Commit Offset을 6번으로 전달하고, 서버는 위에서 설명한 것처럼 두 오프셋을 비교하여 동일함을 확인하고 정상 수행되었다고 판단합니다.
오류 상황 발생 시

그룹이 메시지를 요청하고 서버가 처리하는 과정은 동일합니다. 다만 그룹이 메시지를 처리하지 못해 서버에게 무언가 잘못되었음을 전달합니다. 서버는 이를 확인하고 다시 두 오프셋 사이에 위치한 메시지를 전달합니다. 그리고 나머지 동작은 위에서 설명한 것과 동일합니다.
지금까지 프로듀서와 컨슈머 그룹이 서버로부터 데이터를 가져오는 시나리오를 대략 설명했습니다. 이제 본론으로 돌아와, 속성들을 소개해드리겠습니다.
| 속성 이름 | 서버 0 | 서버 1 | 서버 2 | 서버 3 |
|---|---|---|---|---|
| offsets.topic.replication.factor | 3 | |||
| 토픽의 오프셋들의 복제 개수입니다. 높을 수록 높은 가용성을 보장합니다. | ||||
| transaction.state.log.replication.factor | 3 | |||
| 트랜잭션(transaction) 내 메시지의 복제 개수입니다. 높을 수록 높은 가용성을 보장합니다. | ||||
| transaction.state.log.min.isr | 2 | |||
| min.insync.replicas 속성값을 오버라이드(Override)합니다. 밑에서 설명하겠습니다. | ||||
| min.insync.replicas | 2 | |||
| 프로듀서가 ack을 받기 위한 조건입니다. 프로듀서로부터 얻은 데이터가 기록된 복제본이(위에서 3으로 지정한 것) 해당 속성값의 개수를 충족해야만 프로듀서가 ack를 받습니다. | ||||
로그에 대해서
카프카 공식 사이트에서 로그는 데이터를 복제하고 장애 조치 시 데이터를 동기화하는 목적에 쓰인다고 소개되어있습니다.
Kafka can serve as a kind of external commit-log for a distributed system. The log helps replicate data between nodes and acts as a re-syncing mechanism for failed nodes to restore their data.
그렇다면 로그는 클라이언트가 보낸 메시지를 말하는 걸까요? 아니면 우리가 익히 알고있는 시스템에서 발생하는 이벤트를 기록하는 로그 파일에서의 로그를 말하는 껄까요?
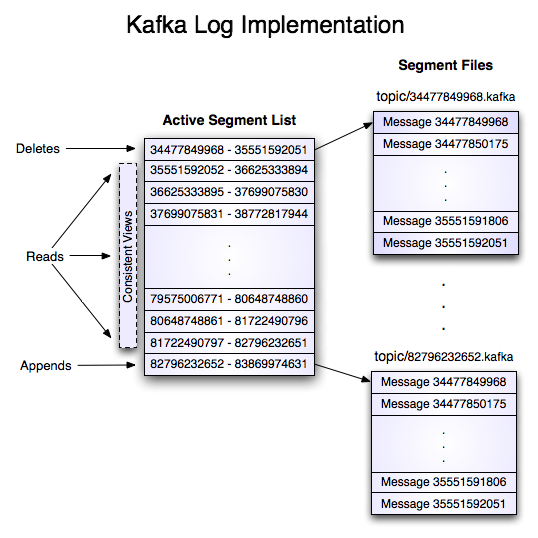
정답은 로그가 메시지의 색인(index) 역할과 더불어 메시지를 보존하는 역할이라는 것입니다.
더욱 자세한 내용은 다음 포스팅에서 다루기로하고, 지금은 속성 기본값만 대입해줍니다.
| 속성 이름 | 서버 0 | 서버 1 | 서버 2 | 서버 3 |
|---|---|---|---|---|
| log.retention.hours | 168 (기본값) | |||
| 로그 파일의 유지 시간입니다. 즉, 해당 시간이 지나면 삭제됩니다. | ||||
| log.segment.bytes | 1073741824 (기본값) | |||
| bytes 단위로, 한 로그 파일의 최대 크기입니다. | ||||
| log.retention.check.interval.ms | 300000 | |||
| ms 단위로, 로그 클리너(log cleaner)가 삭제 가능한 로그를 찾는 시간 주기입니다. | ||||
server.properties 설정 파일 공개
위에서 설정한 모든 값들을 정리하면 아래와 같습니다.
server0.properties
## Server Basics
broker.id=0
## Zookeeper
zookeeper.connect=dim:2181,oim:2181,jim:2181
zookeeper.connection.timeout.ms=10000
## Socket Server Settings
listeners=INTERNAL://dim:19090,EXTERNAL://dim:29090
advertised.listeners=INTERNAL://dim:19090,EXTERNAL://dim:29090
listener.security.protocol.map=INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT
inter.broker.listener.name=INTERNAL
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
## Log Basics
log.dirs=/usr/local/kafka/logs0
num.partitions=1
num.recovery.threads.per.data.dir=1
## Group Coordinator Settings
group.initial.rebalance.delay.ms=3000
## Internal Topic Settings
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
## Log Retention Policy
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
server0이 끝났다면 각 장치에 server1, server2, server3 이름으로 /usr/local/kafka/config 내에 만들어주세요.
서버 실행하기
이미 위에서 환경변수를 등록했다면 다음 명령어를 통해 서버를 실행합니다.
~$ kafka-server-start.sh /usr/local/kafka/config/server0.properties
특별히 오류 메시지가 보이지 않는다면 정상 실행된 것이라고 생각하고 나머지 server1.properties, server2.properties, server3.properties 파일 모두 차례대로 실행시켜 총 4개의 서버를 실행해봅니다!
예제 수행하기
이제 그 기능을 제대로 하는 지 테스트를 해볼 시간입니다.
우선 hello-topic 이름의 토픽을 하나 만들어봅니다. 이때 복제 계수를 3개로, 파티션은 2개로 하여 클러스터가 만들어졌는 지 확인해볼겁니다.
~$ kafka-topics.sh --create --topic hello-topic --zookeeper dim:2181,oim:2181,jim:2181 --replication-factor 3 --partitions 2
Created topic hello-topic.
--describe 옵션을 통해 토픽에 대한 정보를 얻을 수 있습니다.
denny@dim:~$ kafka-topics.sh --describe --topic hello-topic --zookeeper dim:2181,oim:2181,jim:2181
Topic: hello-topic PartitionCount: 2 ReplicationFactor: 3 Configs:
Topic: hello-topic Partition: 0 Leader: 0 Replicas: 0,1,2 Isr: 0,1,2
Topic: hello-topic Partition: 1 Leader: 1 Replicas: 1,2,3 Isr: 1,2,3
위와 같이 파티션이 2개고, Replicas가 3개면 정상입니다.
이제 간단하게 프로듀서와 컨슈머 그룹을 만들어 통신해보겠습니다.
먼저 프로듀서를 실행합니다.
~$ kafka-console-producer.sh --topic hello-topic --bootstrap-server dim:29090
>
이후 컨슈머 그룹도 실행합니다.
~$ kafka-console-consumer.sh --bootstrap-server oim:29090 --topic hello-topic --from-beginning --formatter kafka.tools.DefaultMessageFormatter
이제 프로듀서가 실행된 콘솔창에서 마음대로 메시지를 작성해보세요!
>hello kafka!
>this is message 1.
>this is message 2.
>그렇다면 컨슈머가 실행된 콘솔에서도 동일하게 출력되어야 합니다.
hello kafka!
this is message 1.
this is message 2.
여기까지 왔다면 카프카 클러스터를 성공적으로 구축한 것입니다!
끝내면서
사실 이번이 가장 많이 헤맸던 포스팅 같네요. 애매하게 아는 것만으로는 정확하게 구현하지 못하기 때문에 더욱 자세하게 파고들어 이해하려고 노력했던 것 같습니다...
사실 쓸 말은 해당 포스트 분량의 2배가 더 있는데, 지금 계속 주구장창 터놓는 것보다는 다음 포스트에서 직접 예제를 다뤄보며 알아가는 데 나을 듯 싶어 보류해 놓았습니다.
는 변명이고 사실 지금,
공유기가 포트 포워딩 기능이 고장나
한참 헤맸기 때문에 조금 쉬어야 겠어요.
다음 포스팅에서는 더욱 다양한 요소들을 소개하는 글이 되었으면 좋겠습니다.
고생하셨습니다.
'빅데이터 플랫폼 (Bigdata Platforms) > 아파치 카프카 (Apache Kafka)' 카테고리의 다른 글
| 카프카 (Apache Kafka) 1. 개요 (1) | 2021.01.13 |
|---|