2021. 1. 13. 12:30ㆍ빅데이터 플랫폼 (Bigdata Platforms)/아파치 카프카 (Apache Kafka)

시작하면서
카프카는 2011년 미국 기업인 링크드인(Linkedin)에서 출발했습니다.
사실 그 전부터 기업들은 빅데이터를 모으기 위해 웹사이트에서 발생하는 여러 이벤트 정보들을 수집하기 시작했고, 더 빠르고 더 많은 데이터를 수집하고 저장할 수 있는 플랫폼에 대한 고민이 있었습니다.
그리고 카프카는 아래 5개의 동기와 함께 위의 욕구를 만족하는 플랫폼으로 현재까지 매우 사랑받고 있습니다.
- 거대한 데이터 스트림을 빠르게 처리(high-throughput)할 수 있다
- 오프라인 시스템에서 주기적으로(periodic) 데이터를 읽을 수 있도록 해야한다.
- 데이터 전송에 대한 지연 시간은 매우 작아야 한다.
- 분할 또는 분산되어 실시간으로 데이터를 처리한다.
- 실패(machine failures) 시 빠르게 이를 복구할 수 있다.(fault-tolerance)
- It would have to have high-throughput to support high volume event streams such as real-time log aggregation.
- It would need to deal gracefully with large data backlogs to be able to support periodic data loads from offline systems.
- It also meant the system would have to handle low-latency delivery to handle more traditional messaging use-cases.
- We wanted to support partitioned, distributed, real-time processing of these feeds to create new, derived feeds. This motivated our partitioning and consumer model.
- Finally in cases where the stream is fed into other data systems for serving, we knew the system would have to be able to guarantee fault-tolerance in the presence of machine failures.
왜 하필 카프카를 써야될까?
카프카와 Pulsar, 래빗MQ 중 누가 더 빠를까? - 카프카 입장에서 객관적(?)으로
Benchmarking Kafka vs. Pulsar vs. RabbitMQ: Which is Fastest?
Is Apache Kafka the fastest messaging system in the world? We benchmark each system to determine performance, throughput, and latency at scale.
www.confluent.io
래빗MQ 벤치마크 테스트 및 고찰 - 래빗MQ 입장에서
RabbitMQ » Performance - Messaging that just works
This is the start of a short series where we look at sizing your RabbitMQ clusters. The actual sizing wholly depends on your hardware and workload, so rather than tell you how many CPUs and how much RAM you should provision, we’ll create some general gui
www.rabbitmq.com
사실 각 플랫폼이 목적에 따라 다르다고는 하지만, 역시 앞서 언급했던 5가지에 대해 카프카는 최상위에 위치하고 있습니다.
위 포스팅을 참고하면 카프카를 사용할 이유는, 사용하지 않을 이유가 없기 때문입니다. 하지만 구체적으로 어떻게 메시지를 전달하는 지 알아야봐야 되겠죠? 이제 자세히 들여다보겠습니다.
메시징 모델
카프카는 프로듀서(producer) - 브로커(broker) - 컨슈머(consumer) 구조를 가지고 있습니다.
이를 설명하기에 앞서, 우선 큐잉(queueing)과 퍼블리싱&서브스크라이빙(publising&subscribing)의 두 모델에 대해 설명드리겠습니다.
큐잉 모델

먼저 브로커는 메시지를 담을 수 있는 큐를 준비합니다. 이때 프로듀서들은 메시지를 해당 브로커에게 보내는 데, 브로커는 가지고 있던 큐에 해당 메시지를 적재합니다. 그리고 컨슈머들은 큐를 방문하여 메시지를 가져옵니다.
위 그림을 예로 들면 트리, 펭귄, 베어 순으로 메시지를 시간순으로 A1, A2, B1을 브로커에게 보냅니다. 브로커는 단지 해당 메시지를 큐에 적재하므로 큐에는 그림과 같으며, 산타, 눈남, 돌프가 큐에 있는 A1, A2, B1 를 해당 시간순으로 다시 가져옵니다.
해당 방법의 장점은 프로듀서가 메시지를 보내는 것과 컨슈머가 메시지를 가져오는 것이 병렬로 처리될 수 있다는 점입니다. 하지만 큐의 개수에 대한 오버헤드가 존재하며 큐 내부의 메시지에 대한 주제를 컨슈머가 알아내야 된다는 단점이 있습니다. 또한 한 컨슈머가 메시지를 가져왔다면, 해당 메시지는 다른 컨슈머가 가져올 수 없습니다.
퍼블리싱&서브스크라이빙

이전과 달리 브로커는 여러 개의 토픽을 준비합니다. 이때 각 토픽들은 메시지를 담을 수 있는 큐가 있습니다. 컨슈머는 자신이 원하는 토픽만을 골라 구독하기로 하면, 해당 토픽으로 메시지가 전송될 때 이를 받을 수 있습니다. 만약 한 토픽에 두 컨슈머가 구독했다면, 브로커는 두 컨슈머에게 동일한 메시지 2개를 보냅니다.
위 그림을 예로 들면 트리, 펭귄, 베어가 메시지를 이전과 동일한 순서로 브로커에게 보냅니다. 이때 알파벳을 토픽의 종류로, 숫자를 메시지를 구분하는 번호로 쓰인다고 하면 브로커는 해당 메시지들을 받아 순서대로 각 토픽에 맞게 적재합니다. 그리고 만일 이전에 산타와 눈남이 토픽 A를, 돌프가 토픽 B를 구독했다면 각 구독자들에게 맞는 토픽에 따라 메시지를 전달합니다.
해당 방법의 장점은 메시지를 각 토픽에 분산함으로 컨슈머가 주제를 알아낼 필요는 없고, 여러 컨슈머가 메시지를 병렬로 처리할 수 있다는 점입니다. 하지만 브로커 입장에서 메시지 처리 능력은 오히려 떨어졌다는 큰 단점이 있습니다. 동일 토픽을 구독한 컨슈머의 수에 따라 메시지를 복제하여 전달해야하므로 만일 컨슈머 수가 증가하면, 이에 비례하여 오버헤드가 크게 발생합니다.
카프카 메시징 모델

카프카는 두 모델의 장점만 취한 메시징 모델을 사용했습니다. 기존 큐잉 방식으로 메시지를 전송하되 토픽을 두어 메시지들을 분산하였고, 기존 퍼&서 방식으로 컨슈머가 메시지를 가져오되 컨슈머 그룹(group)으로 컨슈머들을 묶어 해당 그룹이 한 번만 메시지를 가져오도록 했습니다.
따라서 메시지를 보내고 가져오는 것 뿐만 아니라 컨슈머 그룹 내 컨슈머들이 메시지를 병렬로 처리할 수 있습니다. 하지만 브로커는 해당 그룹에게 1번만 메시지를 전달해도 되고, 메시지의 주제 또한 알려줄 필요가 없습니다.
Events are organized and durably stored in topics. ... Topics are partitioned, meaning a topic is spread over a number of "buckets" located on different Kafka brokers. This distributed placement of your data is very important for scalability because it allows client applications to both read and write the data from/to many brokers at the same time.
https://kafka.apache.org/documentation/#intro_concepts_and_terms
당연히 브로커가 1개라면 수 많은 프로듀서와 컨슈머 그룹을 감당하지 못할 수 있습니다. 하지만 카프카는 브로커를 복수 구성하여 해당 브로커들이 동일하게 복제된 토픽들을 가지고 있도록 함으로 분산 처리를 할 수 있도록 지원합니다. 특히 복제된 저장소는 이러한 확장성(scalability)과 유연성(elasticity)뿐만 아니라 내결함성(fault-tolerant)에도 큰 장점을 가집니다.
And all this functionality is provided in a distributed, highly scalable, elastic, fault-tolerant, and secure manner. ... To make your data fault-tolerant and highly-available, every topic can be replicated, even across geo-regions or datacenters, so that there are always multiple brokers that have a copy of the data just in case things go wrong, you want to do maintenance on the brokers, and so on.
https://kafka.apache.org/documentation/#intro_concepts_and_terms
메시지 전송은 어떻게 보장할까?
카프카는 당연히 메시지를 프로듀서로부터 컨슈머에게 전달하는 입장으로써 메시지를 잃지 않도록 보장(guarantee)하는 기능이 있습니다.
그 수준(level)에 따라 아래 중에서 선택할 수 있습니다.
| 종류 | 메시지 상실 | 메시지 재전송 | 설명 |
|---|---|---|---|
| At Most Once | 있을 수 있다 | 안한다 | 메시지를 잃을 수 있지만 재전송은 안한다. |
| At Least Once | 없다 | 한다 | 메시지를 잃는 경우가 없어 재전송할 수 있다. |
| Exactly Once | 없다 | 안한다 | 메시지를 잃는 경우가 없지만 재전송은 안한다. |
당연히 Exactly Once가 가장 좋다고 생각하나요? 사실 해당 수준을 많은 사람들이 사용하고 있지만, 사실 성능상으로는 가장 안 좋습니다. 따라서 카프카 초기에는 메시지 손실을 줄이며 높은 처리량을 요구하기 위해 At Least Once 수준으로 개발되었으며, 이후 Exactly Once 수준으로 확장되었죠.
위 두 수준에 대해 더욱 자세하게 설명하겠습니다.
At Least Once

프로듀서는 카프카 서버에게 메시지를 전송한 후 서버로부터 정상 수신했다는 Act 신호를 받습니다. 만일 Act 신호가 오지 않았거나 실패 신호가 온다면 프로듀서는 다시 메시지를 재전송할 수 있습니다. 마찬가지로 컨슈머가 메시지를 수신한 후 정상 수신했다는 Offset Commit 신호를 보냅니다. 이 신호는 메시지를 얼마나 받았는 지에 대한 오프셋(offset)을 전달합니다. 카프카 서버는 해당 오프셋을 받아 다음 오프셋에 대한 메시지를 전달하는 데, 컨슈머 입장에서는 메시지 수신이 실패했을 경우 해당 메시지부터의 오프셋을 전송하면 됩니다.
Exactly Once
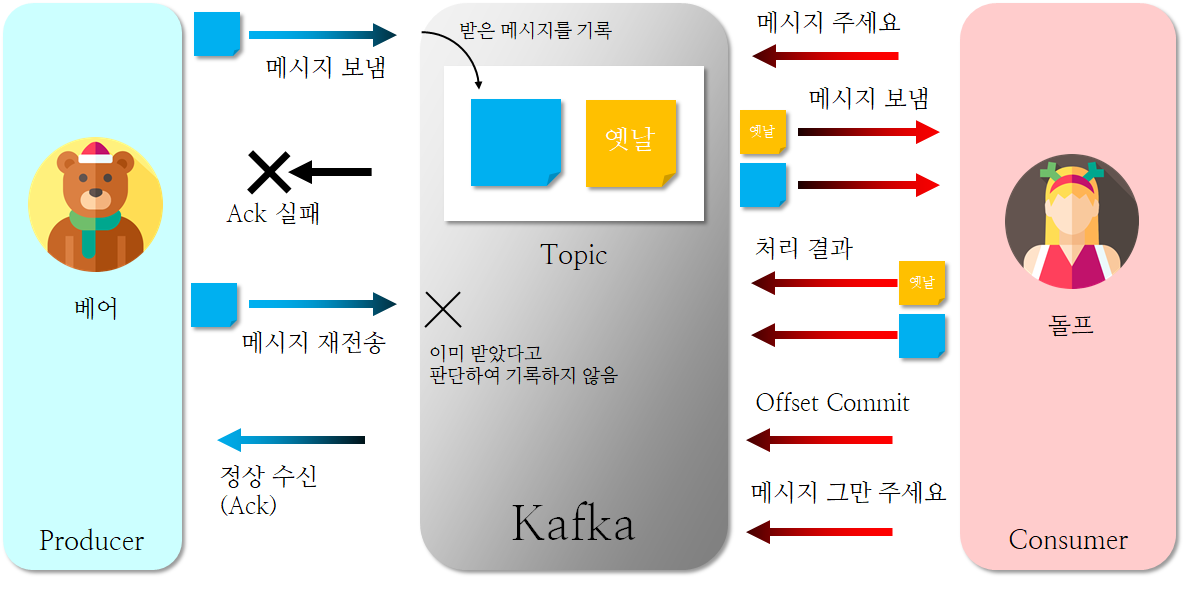
프로듀서 쪽은 At Least Once과 크게 다르지 않습니다. 다만 해당 메시지의 시퀀스 번호를 관리하여 만약 전송된 메시지가 이전에 이미 받아 기록한 메시지라면 다시 기록하지 않습니다. 컨슈머 쪽은 다소 다릅니다. 트랜잭션(transaction) 방법으로 데이터 교환을 수행하는데요. 트랜잭션을 시작하는 신호와 어디부터 읽을 지를 컨슈머가 카프카 서버에게 전달하면, 카프카는 해당 오프셋부터 일정 크기의 메시지들을 전달합니다. 컨슈머 입장에서는 해당 메시지들을 모두 받고 처리한다음 그 결과를 보냅니다. 그리고 정상 수신한 마지막 메시지의 오프셋을 전달합니다. 다시 서버는 해당 오프셋의 다음 오프셋부터 메시지를 전달하는 데, 위 과정을 컨슈머에서 트랜잭션을 종료하거나 트랜잭션이 일정 시간 이루어지지 않을(timeout) 때까지 진행합니다.
여기서 중요하게 짚고 넘어갈 것이 있습니다. 카프카 서버는 다음 두 가지 경우에 대해 Exactly Once 수준을 보장하지 않습니다.
- 메시지를 퍼블리싱할 때
- 메시지를 컨슈밍할 때
카프카를 이용한 스트리밍 시스템에서 완벽한 Exactly Once 수준을 구현하려면, 프로듀서쪽 시스템(upstream system)과 컨슈머쪽 시스템(downstream system) 모두 오프셋과 상태 관리를 구현해야 됩니다.
It's worth noting that this breaks down into two problems: the durability guarantees for publishing a message and the guarantees when consuming a message. ... (i.e. they don't translate to the case where consumers or producers can fail, cases where there are multiple consumer processes, or cases where data written to disk can be lost).
끝내면서
이상으로 카프카에 대한 기본 개념에 대해 알아보았습니다.
어떤 플랫폼이든 똑같이 생각하는 건 직접 구현해보며 학습하는 것이 가장 좋다고 생각합니다.
다음 포스팅에서는 직접 카프카를 설치하고, 구현해보며 카프카를 심층적으로 공부해보도록 하겠습니다.
참고자료
참고도서 : 실전 아파치 카프카 - 사사키 도루 외 4인
카프카 문서 : https://kafka.apache.org/documentation
카프카와 래빗MQ의 차이점 : https://tanzu.vmware.com/developer/blog/understanding-the-differences-between-rabbitmq-vs-kafka/
'빅데이터 플랫폼 (Bigdata Platforms) > 아파치 카프카 (Apache Kafka)' 카테고리의 다른 글
| 카프카 (Apache Kafka) 2. 카프카 설치하기 (0) | 2021.01.22 |
|---|