2021. 2. 22. 13:53ㆍ빅데이터 플랫폼 (Bigdata Platforms)/아파치 하둡 (Apache Hadoop)
시작하기 전
이전 포스팅에서는 하둡을 설치하는 방법에 대해 알아보았습니다.
이때 설정 파일 중 yarn-site.xml 파일을 건드렸었는데, 이는 YARN과 관련이 있습니다.

위처럼 YARN이 하둡 생태계에서 어떤 역할을 하는지, 이번 기회에 알아보는 시간을 가지도록 하겠습니다.
참고
작년 7월 경 Hadoop Common Jira에서 마스터/슬레이브의 용어에 대한 이슈가 있었지만, 아직 해결되지 않은 것 같습니다.
https://issues.apache.org/jira/browse/HADOOP-17170
용어 정의가 변경될 때까지 마스터/세컨더리로 부르겠습니다.
등장 배경
하둡이 등장한 시점에, 사실 YARN은 포함되지 않았습니다. 그 당시 하둡은 크게 HDFS와 맵리듀스(MapReduce) 방식으로 이루어졌었죠.
하둡의 맵리듀스는 데이터를 병렬 분산 처리하는 방법으로써, 매우 큰 크기의 데이터를 처리하기가 매우 용이했습니다. 하둡이 알아서 쉽고 효율적으로 데이터를 각 컴퓨터에게 분배하여 고가용성(High-Availability)을 보장하면서 병렬 연산을 수행했기 때문이죠.
그리고 이러한 맵리듀스 방법은 빅데이터를 처리하는 데 매우 효과적이었습니다. 기존에는 하나의 컴퓨터에서 프로세스를 돌리다가 데이터를 담을 메모리 공간이 부족해지면 그만큼 컴퓨터를 뜯어 메모리를 더 큰 용량으로 교체해야 되었지만, 위 방식을 사용하면 그냥 맵리듀스 서버에 컴퓨터를 추가로 확장하거나 메모리 할당량을 변경하는 등 저비용으로 유연한 대처를 할 수 있었죠. 당연히 적은 메모리를 사용하는 프로세스의 경우, 해당 프로세스에 대해 메모리 할당량을 줄이고 다른 곳에 할당시킬 수도 있습니다.
Hadoop MapReduce is a software framework for easily writing applications which process vast amounts of data (multi-terabyte data-sets) in-parallel on large clusters (thousands of nodes) of commodity hardware in a reliable, fault-tolerant manner.
Hadoop: The Definitive Guide - Tom. W.
YARN의 등장
맵리듀스는 이전에도 설명했듯, 그 장점 때문에 계속 덩치가 커지고 있었습니다. 처음에는 맵리듀스를 위한 모든 기능이 하나에 집약되어 있었지만, 시간이 지나면서 크게 두 개로 나뉘게 됩니다. 바로 자원 관리와 분산 처리입니다.

각 컴퓨터에서 메모리가 코어를 얼마나 사용할 수 있는지, 그리고 어떤 응용 프로그램에 대해 해당 자원을 얼마나 할당할 것인지부터, 작업을 스케쥴링하고 감독하는 것까지 기존에서 분리하여 조금 더 체계화할 필요가 있었기 때문입니다.
(여기까지만 들으면 YARN은 자원 관리 쪽이라는 것을 눈치챌 수 있을 거예요.)
따라서 하둡이 버전 2로 업그레이드되면서 YARN을 등장시킵니다.
The fundamental idea of YARN is to split up the functionalities of resource management and job scheduling/monitoring into separate daemons
Hadoop: The Definitive Guide - Tom. W.
YARN의 역할

먼저 하둡 1.0부터 얘기를 해야 될 것 같습니다. (라떼)
용어부터 정리하면, 응용 프로그램에서 맵리듀스를 사용하는 일을 잡(job)이라고 하고, 하나의 잡을 수행하기 위해 실제로 실행되야될 구체적인 여러 개의 작업을 태스크(task)라고 합니다.
맵리듀스 1.0은 이를 위해 두 가지의 데몬 프로세스를 실행하는 데, 바로 잡트래커(jobtracker)와 태스크트래커(tasktracker)입니다. 먼저 잡트래커는 모든 작업을 총괄합니다. 만약 어떤 실행 코드가 주어졌을 때, 잡트래커는 이를 위한 작업을 생성하고 태스크트래커를 만들어 수행하도록 합니다. 따라서 태스크트래커는 실질적으로 작업을 수행하면서 작업 상황이나 결과를 잡트래커에게 보고합니다. 잡트래커는 해당 내용들을 보고 태스크트래커를 관리하면서 최종 결과를 사용자에게 제공하는 것이죠.
The jobtracker coordinates all the jobs run on the system by scheduling tasks to run on tasktrackers. Tasktrackers run tasks and send progress reports to the jobtracker, which keeps a record of the overall progress of each job. If a task fails, the jobtracker can reschedule it on a different tasktracker. In MapReduce 1, the jobtracker takes care of both job scheduling (matching tasks with tasktrackers) and task progress monitoring (keeping track of tasks, restarting failed or slow tasks, and doing task bookkeeping, such as maintaining counter totals).
.Hadoop: The Definitive Guide - Tom. W.
여기서 태스크트래커는 작업 하나를 위해 만들어집니다. 그러므로 작업이 많아져도 하나의 태스크트래커가 부담하는 일은 동일하죠.
반면에 잡트래커는 어떨까요? 태스크트래커가 많아지면 많아질수록 이를 관리하는 작업은 당연히 힘들 겁니다.
따라서 YARN은 태스크트래커의 역할을 몇 개의 요소로 분리합니다. 바로 리소스매니저(resource manager)와 어플리케이션 마스터(application master)입니다. 이를 쉽게 표현하면 자원 분배, 작업 스케줄 및 작업 상태 관리로 분리되었다고 생각하면 됩니다.

위 개요도(architecture)는 하둡 2.0부터 적용되는 YARN의 작업 흐름입니다.
이를 가장 쉽게 이해하는 방법은, 이전글에서 다루었던 설치 과정을 기억하면 됩니다. 이 글의 하둡을 설정하는 단계에서 메모리 수준을 설정하는 대목이 있습니다. 또 경우에 따라 cpu 코어 개수를 할당할 수도 있었죠. 컴퓨터들을 연결하는 데 물론 라우터를 사용했지만, 랙(rack) 또는 센터(center) 단위의 분산 시스템은 어떤가요? 이 경우에는 네트워킹 지연 시간도 고민해보아야 합니다.
이렇듯 리소스 매니저는 각 컴퓨터의 자원 및 네트워크 상황을 기록한 데이터를 가지고 있습니다. 만약 클라이언트가 응용 프로그램을 하둡에게 제출(submit)하면, 리소스 매니저 내 스케쥴러(scheduler) 위 데이터를 가지고 적절히 실행 순서를 제어(control)합니다.
자, 그럼 어떻게 실행할까요?
각 컴퓨터는 노드 매니저 프로세스를 가지고 있습니다. 해당 프로세스 내에서는 컨테이너(container)라는 가상의 작업 공간이 여러 개 있는데, 바로 해당 공간에서 실질적으로 작업이 수행됩니다.
그렇다면 당연하게도 해당 컨테이너를 관리할 어플리케이션 마스터(application master)의 존재의 필요성을 느껴야 됩니다. 제출된 응용 프로그램은 어플리케이션 매니저에게 전달되어 각 컴퓨터의 노드 매니저 중 하나를 선택해 어플리케이션 마스터를 빌드하도록 합니다. 여기서 어플리케이션 마스터는 스케쥴러를 참고하여 본인 또는 다른 컴퓨터의 컨테이너에 본인의 어플리케이션을 수행하도록 하고, 진행 상태를 지속적으로 전달받습니다. 그리고 작업이 완료되면 다시 어플리케이션 마스터에게 결과를 전송합니다. 어플리케이션 마스터는 해당 결과를 다시 클라이언트에게 전달하죠.
위 그림에는 포함되지 않았지만, 타임라인 서버가 별도로 존재하여 모든 작업 진행 상황이나 제출된 응용프로그램 개요 등을 시간과 함께 기록합니다.
그리하여 정리하면
하둡 1.0의 잡트래커는 하둡 2.0+YARN에서 리소스 매니저, 어플리케이션 마스터, 타임라인 서버로 구분되었고
태스크 트래커는 노드 매니저로 슬롯은 컨테이너로 바뀌었습니다.
YARN을 사용하면 무슨 이점이 있는데요?
1. 확장성(Scalability)
YARN은 잡트래커의 역할 중 어플리케이션 마스터와 관련된 역할을 세컨더리 컴퓨터로 분리시켰기 때문에 마스터 컴퓨터의 부하를 줄이거나 작업 정보 수신에 대한 병목(bottlenecks) 현상을 줄일 수 있습니다.
기존 맵리듀스 1.0이 4,000개의 노드를 관리하고 40,000의 작업을 수행할 수 있었다면, 동일한 환경에서 YARN은 10,000개의 노드를 관리하고 100,000의 작업을 수행할 수 있다고 합니다.
Scalability
(Limitation) - Maximum Cluster size - 4,000 nodes, - Maximum concurrent task - 40,000
...
(Requirements) - Clusters of 6,000 - 10,000 machines, - 100,000+ concurrent tasks, - 10,000 concurrent jobshttps://www.slideshare.net/hortonworks/nextgen-apache-hadoop-mapreduce
2. 가용성(Availability)
고가용성(high availability)은 현재 서비스를 다른 곳에 복제하여 준비시키고, 만약 현재 서비스가 실패하면 준비시킨 복제본을 꺼내어 복구함으로 달성됩니다. 잡트래커는 위 과정을 혼자 전부 수행하는 반면, YARN은 복구를 위한 복제본은 마스터 컴퓨터에 있지만 각 세컨더리 컴퓨터에 있는 어플리케이션 마스터가 복제본을 가져와 복구를 수행합니다.
When there are multiple RMs, the configuration (yarn-site.xml) used by clients and nodes is expected to list all the RMs. Clients, ApplicationMasters (AMs) and NodeManagers (NMs) try connecting to the RMs in a round-robin fashion until they hit the Active RM.
https://hadoop.apache.org/docs/r3.3.0/hadoop-yarn/hadoop-yarn-site/ResourceManagerHA.html
따라서 기존의 잡트래커에 대한 부하를 줄임으로 더 빠르고 효율적인 고가용성을 보장할 수 있습니다.
3. 이용성(Utilization)
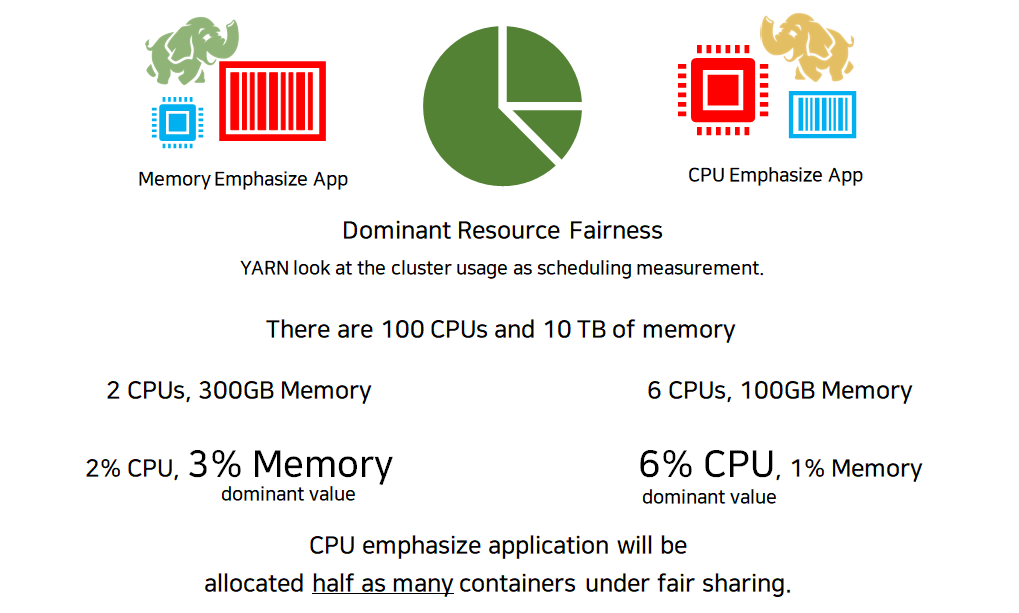
맵리듀스 1.0에서는 각 태스크 트래커가 컴퓨팅 자원에 대해, 설정 시간에서 고정된 크기의 슬롯을 정적으로 할당하는 방식으로 이루어졌습니다. 하지만 YARN의 노드 매니저는 자원 풀(pool)을 관리하여 필요시 적절한 자원을 동적으로 할당합니다.
Furthermore, resources in YARN are fine grained, so an application can make a request for what it needs, rather than for an indivisible slot, which may be too big (which is wasteful of resources) or too small (which may cause a failure) for the particular task.
Hadoop : The Definitive Guide - Tom W.
4. 다중차용성(Multitenancy)

비단 하둡 내 맵리듀스뿐만 아니라 다른 분산 처리 애플리케이션도 YARN을 이용할 수 있습니다. 예로 Spark나 Hive입니다. 비록 다른 맵리듀스 방식을 수행해도 결국 YARN의 자원 관리 서비스를 통해 분산 처리를 효율적으로 할 수 있습니다.
It is even possible for users to run different versions of MapReduce on the same YARN cluster, which makes the process of upgrading MapReduce more manageable.
Hadoop : The Definitive Guide - Tom W.
도대체 맵리듀스가 뭐길래 그래요?
사실 맵리듀스의 개념 자체는 어렵지 않습니다. 오히려 신묘하죠.
간단한 예제 하나를 가져와 봅시다. 언어는 스칼라(설치경로)입니다.
package example
import scala.collection.mutable.Map
import collection.immutable.ListMap
object Hello {
def main(args: Array[String]): Unit = {
var text = "Admiral Yi Sunsin (Korean: 이순신; Hanja: 李舜臣; April 28, 1545 – December 16, 1598) was a Korean admiral and military general famed for his victories against the Japanese navy during the Imjin war in the Joseon Dynasty. Yi has since been celebrated as a national hero in Korea";
var dict = Map[String, Int]();
for (word <- text.split(" ")) {
if (dict.contains(word)) dict(word) = dict(word)+1;
else dict.put(word, 1);
}
for (word_map <- ListMap(dict.toSeq.sortWith(_._2 > _._2):_*)) {
println(word_map)
}
}
}
9-12번 라인을 보면 텍스트를 띄어쓰기 기준으로 나누고, 단어 빈도수를 카운팅 하는 것을 알 수 있습니다. 여기서 주요한 점은 작업이 싱글로 수행된다는 점인데, 이는 곧 단어 하나씩 가져와 한 번씩 수행한다는 것이죠.
다음은 맵리듀스를 사용한 예제입니다. (출처)
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.Path
import org.apache.hadoop.io.IntWritable
import org.apache.hadoop.io.Text
import org.apache.hadoop.mapreduce.Job
import org.apache.hadoop.mapreduce.Mapper
import org.apache.hadoop.mapreduce.Reducer
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat
import org.apache.hadoop.util.GenericOptionsParser
import scala.collection.JavaConversions._
class TokenizerMapper extends Mapper[Object,Text,Text,IntWritable] {
val one = new IntWritable(1)
val word = new Text
override
def map(key:Object, value:Text, context:Mapper[Object,Text,Text,IntWritable]#Context) = {
for (t <- value.toString().split("\\s")) {
word.set(t)
context.write(word, one)
}
}
}
class IntSumReducer extends Reducer[Text,IntWritable,Text,IntWritable] {
override
def reduce(key:Text, values:java.lang.Iterable[IntWritable], context:Reducer[Text,IntWritable,Text,IntWritable]#Context) = {
val sum = values.foldLeft(0) { (t,i) => t + i.get }
context.write(key, new IntWritable(sum))
}
}
object WordCount {
def main(args:Array[String]):Int = {
val conf = new Configuration()
val otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs
if (otherArgs.length != 2) {
println("Usage: wordcount <in> <out>")
return 2
}
val job = new Job(conf, "word count")
job.setJarByClass(classOf[TokenizerMapper])
job.setMapperClass(classOf[TokenizerMapper])
job.setCombinerClass(classOf[IntSumReducer])
job.setReducerClass(classOf[IntSumReducer])
job.setOutputKeyClass(classOf[Text])
job.setOutputValueClass(classOf[IntWritable])
FileInputFormat.addInputPath(job, new Path(args(0)))
FileOutputFormat.setOutputPath(job, new Path((args(1))))
if (job.waitForCompletion(true)) 0 else 1
}
}
핵심은 map 함수와 reduce 함수입니다. map은 위 싱글로 동작하는 예제에서 텍스트를 띄어쓰기로 구분해 나누고, reduce는 단어를 카운팅 한다는 점에서 동작은 동일합니다.
그러나 해당 작업은 분산 병렬 처리로 수행하기 때문에 단어를 하나씩 가져와 수행하는 것과 차이가 있습니다. 이는 단어를 하나씩 가져와 빈도수를 세는 것과 달리 단어를 뿌려놓아서 병렬로 가져와 빈도수를 세는 것이기 때문인데, 아직 이해가 되지 않을 거예요.
다시 위 map과 reduce 함수의 코드를 자세히 보면, context가 계속 등장합니다. 해당 변수의 자료형을 보더라도 Writable로 뭔가를 작성한다는 느낌을 받을 수 있는데요. 이는 분산 병렬 처리의 핵심적인 요소로 작용합니다.
왜 그럴까요?
맵리듀스의 원리

위 그림은 이전 예제 텍스트를 맵리듀스 방식으로 단어의 빈도수를 세는 과정입니다.
단계가 5개로 보이지만, 사실상 입력과 출력은 당연한 것이기 때문에 기억해야 하는 건 맵(map), 셔플(shuffle), 리듀스(reduce) 3개만 있습니다. 그리고 가장 중요한 점은 반드시 위처럼 만들지 않아도 된다는 점입니다. 단순히 단어 빈도수를 세는 단편적인 예시일 뿐, 회귀 모형이나 클러스터링과 같은 다양한 알고리즘을 위 예시처럼이 아니라, 해당 원리를 이용해 구현할 수 있다는 점을 인지해야 합니다.
위 단계를 체계적으로 정리할 수도 있겠지만, 그냥 단순하게 1. 나누고 2. 뿌리고 3. 수집해서 4. 계산한다만 기억하면 됩니다.
먼저 맵은 나누고 뿌리는 과정에 해당합니다.
우리의 목적은 단어의 빈도수를 세는 것이기 때문에 주어진 텍스트가 Admiral Yi Sunsin (Korean: 이순신... 이라면 먼저 단어를 띄어쓰기로 구분해야 합니다.
def map(key:Object, value:Text, context:Mapper[Object,Text,Text,IntWritable]#Context) = {
for (t <- value.toString().split("\\s")) {
...
그리고 뿌립니다(?). 이 용어를 사용한 이유는 수집하는 단계에서는 반드시 전달된 순서대로 작업을 수행하지 않기 때문입니다.
...
context.write(word, one)
}
}
위 코드를 보면 알 수 있듯 데이터 형식은 (키, 값)입니다. 이렇게 구분한 이유는 당연히 각기 다른 쓰임새가 있기 때문이겠죠?
맵이 뿌린 데이터를 수집하는 과정을 셔플이라고 합니다.
셔플은 (키, 값)으로 전달된 데이터를 키를 기준으로 값을 모읍니다. 셔플 단계의 결과를 보면 단어가 키가 되고, 뒤 배열은 해당 키를 가진 값을 모아놓은 것임을 알 수 있습니다. 여기서 모았다는 표현은, 셔플이 값이 무엇인지 신경 쓰지 않는다는 것과 상통합니다. 즉, context에 작성된 단어들은 수집하는 과정에서 순서나 크기를 신경쓰지 않고, 무조건 빠르게 진행합니다.
리듀스는 셔플이 잘 모은 데이터를 가지고 계산을 수행합니다.
사실 대부분의 경우 키를 참조하여 배열을 순회해서 연산합니다.
def reduce(key:Text, values:java.lang.Iterable[IntWritable], context:Reducer[Text,IntWritable,Text,IntWritable]#Context) = {
val sum = values.foldLeft(0) { (t,i) => t + i.get }
...
그리고 그 결과를 다시 (키, 값)으로 전달합니다. 당연하게도, 리듀스가 기록하는 데이터 또한 순서가 없습니다.
...
context.write(key, new IntWritable(sum))
}
}
그리고 출력은 리듀스의 결과를 보여줄 뿐입니다.
그럼 이러한 방식은 어떻게 분산 처리를 가능하게 할까요?
맵리듀스의 분산 컴퓨팅
시작하기 전 Swivel: Improving Embeddings by Noticing What’s Missing - Noam S., Ryan D., Colin E., Chris W. 논문이 기억나서 공유해봅니다.
3페이지를 보면 이런 설명이 있어요.
As will be discussed in more detail below, splitting the matrix into shards allows the problem to be distributed across many workers in a way that allows for utilization of high performance vectorized hardware, amortizes the overhead of transferring model parameters, and distributes parameter updates evenly across the feature embeddings.
Swivel: Improving Embeddings by Noticing What’s Missing - Noam S., Ryan D., Colin E., Chris W.

그림에서 왼쪽을 보면 큰 덩어리에서 작은 여러 개의 덩어리로 바뀌었고, 오른쪽을 보면 그 작은 덩어리에 하나하나를 구분할 수 있습니다. 마치 행렬(matrix)과 같이 생겼네요.
이때 분산 처리가 가능한 건 바로 그 작은 덩어리가 독립적이라는 것에 있습니다.

4명의 워커가 위 그림처럼 존재한다고 합니다. 이때 각 워커는 네모를 자신이 할 수 있을 만큼 가져와 연산합니다.
각 워커는 네모가 좋은지 나쁜지 판단할 줄 모르기 때문에 그냥 빠르게 가져올 수 있는 대로 네모를 선택해 가져옵니다. 그리고 연산이 끝나면 그 결과를 원래 있던 자리에 적어놓고(또는 독립된 다른 장소에 적습니다.) 다른 네모를 선택합니다.
위 과정을 반복한다고 했을 때, 머릿속으로 네모를 워커들이 가져가는 걸 상상하면 분산 처리가 이해가 될 것입니다! 맵리듀스의 핵심은 그저 이 워커를 다른 컴퓨터에 배치시킬 수 있다는 확장성(scalability)에 있습니다. 물론 정말 성능이 뛰어난 워커 한 명으로 병렬 처리를 시킬 수 있다면 좋겠지만, 성능과 비용은 완벽히 비례하지 않습니다.
아래는 CPU 벤치마크 사이트에서 인용한 CPU 성능과 가격표입니다.

AMD Ryzen Threadripper 3990X 하나를 사용해서 80,889의 성능을 뽑아도 되지만, Intel Core i5-10500 @ 3.10GHz 20개가량을 사용해 더 좋은 성능을 가질 수 있죠. 더욱 중요한 건 확장성이기 때문에 만약 더 좋은 성능을 가지고 싶을 때 다시 거금을 들여 수백만 원짜리 CPU를 추가로 구매하여 대체하는 것보다 그저 하나 더 구매하고 맵리듀스 자원에 추가하면 됩니다.
따라서 하둡의 기본 목적 중 저비용으로 높은 처리량을 보장한다는 것이 이제는 이해가 될까요?
YARN 스케쥴링
마지막으로 YARN이 가지고 있는 스케쥴링 정책에 대해서 알아보겠습니다.

위 그림은 3가지 다른 정책을 표현하고 있습니다.
먼저 FIFO(First-In, First-Out)는 단순히 큐에 먼저 들어온 순서대로 먼저 처리하는 방식입니다. 쉽죠?
Capacity는 요구 자원량을 기준으로 미리 큐를 여러 개 만들어놓고, 작업을 알맞게 할당합니다. 큐 하나의 내부는 FIFO 정책을 따르고 있습니다.
With the Capacity Scheduler (ii in Figure 4-3), a separate dedicated queue allows the small job to start as soon as it is submitted, although this is at the cost of overall cluster utilization since the queue capacity is reserved for jobs in that queue.
Hadoop: The Definitive Guide - Tom. W.
Fair은 모든 애플리케이션을 동일하게 스케쥴링하는 방식입니다.
사실 어떤 스케쥴링 정책을 사용할지는, 각각의 작업이 언제 끝나는지에 따라 달렸습니다. FIFO의 경우에는 1번 작업이 가장 빨리 끝난 반면 2, 3번 작업은 매우 늦게 끝납니다. Capacity의 경우 2, 3번이 비교적 빨리 끝나고 1번이 가장 늦게 끝납니다. Fair의 경우에는 Capacity보다 2, 3번이 더 일찍 끝나는 것을 볼 수 있는데 그렇다고 속으면 안 됩니다. Fair 방식은 모든 애플리케이션을 동등하게 할당하기 때문에 만약 많은 수의 애플리케이션이 수행된다면 2, 3번이 더 느리게 끝날 수도 있습니다.
끝내면서
오랫동안 포스팅을 쉬었네요.
이제 다시 열심히 작성해야겠어요 ㅎ.
이상으로 YARN에 대한 포스팅을 마칩니다. 읽어주셔서 감사합니다!
'빅데이터 플랫폼 (Bigdata Platforms) > 아파치 하둡 (Apache Hadoop)' 카테고리의 다른 글
| 하둡 (Apache Hadoop) 4. Zookeeper로 HDFS의 고가용성(High Availability) 달성하기 (0) | 2021.02.22 |
|---|---|
| 하둡 (Apache Hadoop) 2. 하둡 완전 분산 모드 구현하기 (1) | 2021.01.07 |
| 하둡 (Apache Hadoop) 1. HDFS 개요 (0) | 2021.01.06 |