2021. 1. 6. 16:36ㆍ빅데이터 플랫폼 (Bigdata Platforms)/아파치 하둡 (Apache Hadoop)
시작하면서
아파치(apache) 빅데이터 프로젝트 내 하둡 생태계(hadoop echosystem) 중 파일시스템(filesystem)입니다.

HDFS는 단순히 하둡 분산 파일 시스템(Hadoop Distributed File System)을 줄여 부르는 말입니다. 이는 여러 개의 하드웨어(저장소)를 묶은 하나의 파일 시스템이라고 생각하면 됩니다. 실제 HDFS를 사용해보면 현실 속에서 저장소가 분산되었지만, 마치 하나의 파일 시스템을 쓰는 것과 같은 느낌을 받을 수 있습니다. 이를 하둡에서 개발했기 때문에 위와 같은 이름이 붙었습니다.
The Hadoop Distributed File System (HDFS) is a distributed file system designed to run on commodity hardware.
왜 HDFS를 사용해야 하나요?
단지 여러 개의 하드웨어를 사용한다고 해서는 큰 의미가 없습니다. 대용량 저장소를 구매하면 더 빠르고 쉽게 파일에 접근할 수 있을 테니까요. 하지만 HDFS가 기존 파일 시스템과 분명히 구별되는 장점은 저비용으로 높은 가용성을 보장한다는 점입니다. 뿐만 아니라 보다 빠르게 대용량 데이터 집합을 가져올 수 있습니다.
HDFS is highly fault-tolerant and is designed to be deployed on low-cost hardware. HDFS provieds high throughput access to application data and is suitable for applications that have large data sets.
이런 일이 어떻게 일어날 수 있을까요?
자, 다시 장점을 큰 범주로 정리하겠습니다.
이전에 소개했던 내용에 몇 개를 더 추가했습니다.
- 대용량 데이터를 저장하고, 빠르게 읽을 수 있다.
- 여러 개로 분산된 저장소를 하나의 파일 시스템처럼 사용하며 원격으로 접속할 수 있다.
- 매우 많은 파일들을 저장해도 빠르게 접근할 수 있다.
- 저비용으로 높은 가용성을 가진다.
이제 차근차근 설명해보겠습니다.
1. 대용량 데이터를 저장할 수 있으며 빠르게 읽을 수 있다.
사실 대용량 데이터를 저장하지만, 파일 시스템 내 어떤 대단한 압축 알고리즘을 가지는 것도 아니고 높은 가용성을 지니려면 복제본을 저장할 추가 용량이 필요합니다. 하지만 그럼에도 불구하고 각 클라이언트(컴퓨터)는 본인이 가지고 있는 저렴한 저장소 용량보다 더 큰 용량을 필요로 하는 파일일지라도, 다른 클라이언트의 저장소를 이용함으로 저장 용량을 더 크게 사용할 수 있습니다.
기본적으로 파일 시스템은 파일을 저장하기 위해 블록 단위를 사용합니다.

만약에 512B 크기의 블록을 정의한다면, 256B 크기의 파일을 저장해야 할 때 어떻게 할까요?
그러면 해당 파일을 위해서 블록 하나를 할당해줍니다.
마찬가지로 756B 크기의 파일이라면 블록을 몇 개 할당해줘야 될까요? 맞습니다, 2개입니다. (512B+244B)
In [0] : print( Question("그럼 나머지 공간은 어떻게 될까요?") )
Out [1] : 빈 공간이 됩니다. ^^.따라서 블록의 크기를 너무 작게 잡으면 참조 시간이 길고, 너무 크게 잡으면 저장소에 빈 공간이 많아질 것입니다.
그런데 이상하게도 HDFS는 128MB 이상의 너무 큰 블록 크기를 가지고 있습니다. (64MB를 사용하는 경우도 있어요, 어쨌든 크네요.)

이런 블록으로는 조그마한 파일 몇 개를 저장했을 때, 금방 저장 용량을 초과할 것 같습니다. 하지만 자세히 보면 이는 '가상 블록 크기'입니다. 즉 조그마한 파일 몇 개는 실제로 해당 파일 크기만큼 저장소 공간을 사용하고, 대신 마치 각 파일들이 128MB 크기의 블록을 사용하고 있다고 가정하여 참조하는 것입니다.
In [0] : print( Question("헷갈리게 그런 가정은 왜 하는 건가요?") )
Out [1] : 그래서 대용량 데이터를 다루기가 용이합니다.128GB의 큰 파일 하나를 생각해봅시다. (사실 그렇게 큰 크기도 아닙니다)
해당 파일을 Unix 파일 시스템과 HDFS 두 파일 시스템에 저장한다고 가정하고, 각 512B와 128MB의 블록 크기를 가진다고 가정했을 때,
$$
UnixFS = (128_1024_1024*1024)/(512) = 268,435,456 개
$$
$$
HDFS = (128_1024_1024_1024)/(128_1024*1024) = 1,024 개
$$
파일을 읽고 싶을 때 작은 블록 크기는 수많은 블록 참조 횟수를 이끌어냅니다. 물론 어느 정도 블록들이 인접하게 위치하겠지만 반드시 그렇지도 않기 때문에 Unix 파일 시스템은 HDFS보다 바쁘게 파일을 전송해야 되겠죠.
HDFS is designed to support very large files. Applications that are compatible with HDFS are those that deal with large data sets. These applications write their data only once but they read it one or more times and require these reads to be satisfied at streaming speeds. HDFS supports write-once-read-many semantics on files. A typical block size used by HDFS is 128 MB. Thus, an HDFS file is chopped up into 128 MB chunks, and if possible, each chunk will reside on a different DataNode.
대용량 데이터를 빠르게 읽도록 하는 노력은 아직 3가지나 더 있습니다.
- 여러 개의 프로세스로부터의 데이터 읽기
- 네트워크 토폴로지
- 페더레이션
프로세스는 프로그램 실행 단위를 말합니다. 클라이언트가 데이터를 요구했을 때, 당연히 서버 쪽에서는 데이터를 전송하는 프로세스가, 클라이언트 쪽에서는 해당 데이터에 대해 응답하는 프로세스가 실행됩니다.
이때 HDFS는 데이터를 전송할 때 한 하나의 프로세스를 거치지 않습니다. 가령 데이터가 A, B, C 노드에 분산되어 있다고 가정했을 때 각 A, B, C는 데이터 전송을 위해 프로세스 A, 프로세스 B, 프로세스 C를 생성하며 클라이언트는 네트워크 대역폭이 허락하는 한 세 지점으로부터 데이터를 수집합니다.
100의 데이터를 받기 위해 10마다 1의 지연시간과 10의 트랜잭션 시간이 존재한다고 가정했을 때, 1:1 통신과 n:1 통신 시간은 다음 그림과 같습니다.

전체적으로 여러 개의 프로세스를 가진 후자가 조금 더 빠릅니다.
그렇다면 분산 파일 시스템이라서 가지는 단점은 어떨까요?
파일이 분산되었으면 해당 분산된 파일을 찾는 것도 하나의 일이 됩니다.
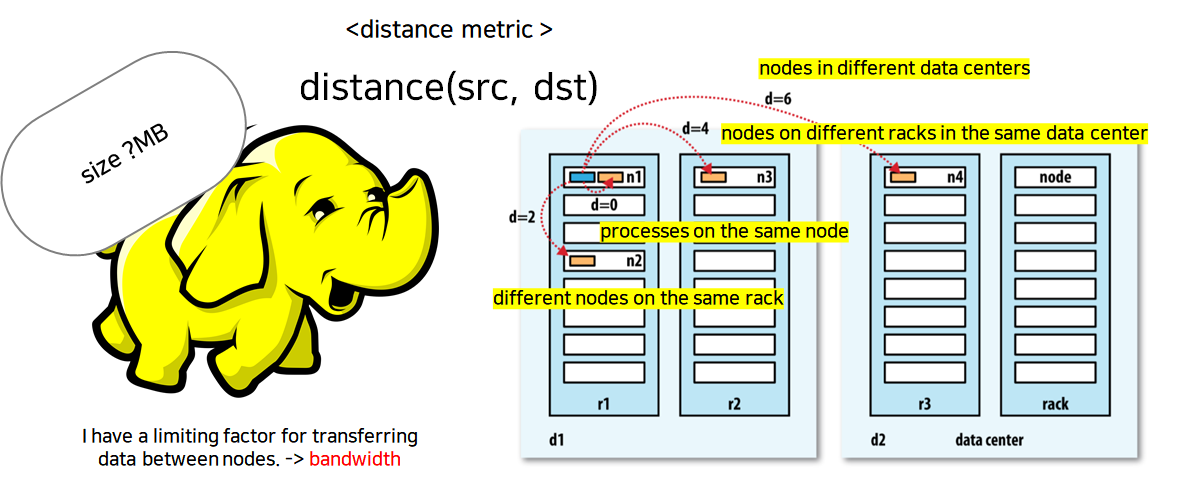
이를 위해 HDFS는 가장 파일을 찾기 위한 가장 짧은 거리 값, 즉 대역폭(bandwidth)을 찾을 수 있도록 네트워크 토폴로지(network topology)를 지원합니다.
위 그림에서 볼 수 있듯 각 데이터센터 - 랙(Rack) - 노드들은 트리(tree) 구조로 저장되어 있습니다. 간단한 아이디어로, 본인 노드와 최대한 가까운 파일을 가지는 노드로부터 데이터를 받을 수 있습니다.
마지막으로 페더레이션(federation)입니다. 이는 정보 통신에서의 개념과 다르게 모든 네임노드를 메모리에 적재하는 방식입니다. 이는 다음 챕터에서 더욱 상세히 설명하겠습니다.
Applications that run on HDFS need streaming access to their data sets. They are not general purpose applications that typically run on general purpose file systems. HDFS is designed more ** for batch processing rather than interactive use by users.**
여기서 잠깐, '처리량'과 '지연 시간'은 다른 말이에요.
분명 HDFS는 대용량 데이터 전송에 빠른 시간을 가지고 있습니다. 하지만 위에서 이미 소개했듯 분산된 저장소는 '네트워크'로부터 데이터를 전송해야 되는 단점이 있고, 아무래도 저장소 하나만을 사용하는 것보다 외부로부터 데이터를 읽는 과정이 지연시간이 매우 클 것입니다. 즉, 100GB 데이터를 처리할 때 HDFS가 빠른 이유는 데이터 처리량이 커서이지, 데이터 전송 지연 시간이 빨라서 그런 것이 아닙니다.
The emphasis is on high throughput of data access rather than low latency of data access. POSIX imposes many hard requirements that are not needed for applications that are targeted for HDFS. POSIX semantics in a few key areas has been traded to increase data throughput rates.
2. 매우 많은 파일들을 저장해도 빠르게 접근할 수 있다.
이전에 패더레이션(federation)에 대해 잠깐 언급했었습니다.
정확히 개념을 설명하기 위해, 먼저 HDFS의 배경을 설명해드리겠습니다. HDFS는 기본적으로 네임스페이스와 블록 저장소 서비스, 이 두 개의 레이어로 나뉩니다.

이미지에서 볼 수 있듯, 두 레이어와 다르게 구별되는 네임노드와 데이터노드가 있어요. 해당 네임노드로 공유되는 데이터노드를 다룰 수 있어요.
HDFS has two main layers: 1) Namespace ... , 2) Block Storage Service ...

각 네임노드는 각 사용자의 컴퓨터에 독립적으로 저장됩니다. 이 말은, 저장소에 있는 데이터노드를 다룰 수 있는 네임노드를 동일하게 쿠키, 펭귄, 베어가 가지고 있다는 의미예요. 사실 네임노드 안에는 블록 풀(block pool)이라고 각 사용자가 독립적으로 네임노드를 사용할 수 있도록 합니다. 가령 쿠키가 네임노드를 통해 어떤 데이터노드를 변경하다가 실패해도, 펭귄과 베어는 영향을 받지 않고 본인의 네임노드를 사용할 수 있는 것이죠!
A Block Pool is a set of blocks that belong to a single namespace. Datanodes store blocks for all the block pools in the cluster. Each Block Pool is managed independently. This allows a namespace to generate Block IDs for new blocks without the need for coordination with the other namespaces. A Namenode failure does not prevent the Datanode from serving other Namenodes in the cluster.

이런 네임노드는 각 사용자의 메모리에 상주합니다. 이를 HDFS 페더레이션이라고 합니다. 장점은 빠르다는 것이지만 단점은 시스템 자원을 많이 잡아먹을 수 있다는 점입니다.
3. 분산된 저장소를 하나의 파일 시스템처럼 사용하며 원격 접속할 수 있다.
해당 내용은 다음 장에서 직접 HDFS를 사용하는 모습을 보여드리며 설명하겠습니다.
4. 저비용으로 높은 가용성을 가진다.

가령 500MB 크기의 텍스트 파일 하나를 열어본다고 가정할게요.
용량이 꽤나 큰 텍스트 파일의 경우에는 여는 것도 버겁지만, 기다리다 갑자기 오류가 나서 메모장이 닫혔다고 해볼게요.
try { ... } except {
print("열받게 하지마...")
}1GB 절반 남짓의 크기에도 오류가 날 수 있다면, 하물며 수 테라바이트의 데이터는 어떻게 처리해야 할까요?
사실 HDFS 클러스터가 고장 날 상황은 다음 두 가지입니다.
- 어느 장치가 고장 나서 네임노드를 다시 실행하는 것조차 불가능할 때.
- 소프트웨어나 하드웨어 업그레이드가 수행되어 하둡 프로세스를 계속 사용하지 못할 때.
This impacted the total availability of the HDFS cluster in two major ways :
* In the case of an unplanned event such as a machine crash, the cluster would be unavailable until an operator restarted the NameNode.
* Planned maintenance events such as software or hardware upgrades on the NameNode machine would result in windows of cluster downtime.
HDFS를 쓰는 가장 기본적인 이유 중 하나인 높은 가용성은, 각 클러스터 노드(하드웨어)들에게 퍼져있는 네임노드를 이용하여 활성화(active)된 하나의 네임노드가 실패할 것을 대비해 준비(standby) 상태의 네임노드를 대비해놓는 것입니다. 그렇다면 당연히 활성화된 네임노드는 본인의 진행상황을 실시간으로 보고해야 되고, 준비 상태의 네임노드는 진행상황을 감독하며 알맞은 준비태세를 갖추어야 되겠죠.
자, 정리하면 앞서 설명한 활성화된 네임노드(active stated namenode)는 본인의 진행 상황을 공유 저장소 내 에디트 로그(edit log) 파일에 작성해야 합니다. 그리고 준비 상태의 네임노드(secondary namenode)는 해당 파일을 감시하면서 동기화(발을 맞추고)하고, 만약 오류가 났을 때 해당 네임노드를 대체하여 작업을 수행합니다(failover).
In a typical HA cluster, two or more separate machines are configured as NameNodes. At any point in time, exactly one of the NameNodes is in an Active state, and the others are in a Standby state. The Active NameNode is responsible for all client operations in the cluster, while the Standby is simply acting as a slave, maintaining enough state to provide a fast failover if necessary. In order for the Standby nodes to keep their state synchronized with the Active node, the current implementation requires that the nodes have access to a directory on a shared storage device (eg an NFS mount from a NAS).
잠깐, 높은 가용성은 빠른 오류 대처를 포함해요.
당연히 느린 오류 대처는 가용성이 높다고 할 수 없어요. 어떤 오류를 극복하는 데 1시간이나 걸려서 진행이 지연된다면, 그건 문제를 해결해도 해결한 것이 아니에요! HDFS의 높은 가용성은, 준비 상태의 네임노드가 되도록 신속하고 정확하게 결함이 있는 네임노드를 대체하기 때문에 의미가 있습니다.

고가용성은 앞서 언급했던 공유되는 네트워크 저장소를 사용하는 NFS(Network FileSystem) 방식과, 주키퍼(zookeeper)를 사용하여 ssh와 같은 원격 시스템을 통해, 액티브 네임노드가 기록한 진행 상황(journal)을 다른 네임노드가 볼 수 있도록 하는 QJM(Quorum Journal Manager) 방식이 있습니다.
현재는 주키퍼에 대한 챕터를 작성하기 전이므로, NFS에 대해 고가용성을 튜닝하는 것을 먼저 하둡 시스템을 구축하면서 소개해볼게요.
In a typical HA cluster, two or more separate machines are configured as NameNodes. At any point in time, exactly one of the NameNodes is in an Active state, and the others are in a Standby state. The Active NameNode is responsible for all client operations in the cluster, while the Standby is simply acting as a slave, maintaining enough state to provide a fast failover if necessary. In order for the Standby nodes to keep their state synchronized with the Active node, the current implementation requires that the nodes have access to a directory on a shared storage device (eg an NFS mount from a NAS).
끝내면서
이상으로 HDFS에 대한 개요를 작성해보았어요.
작성하다 보니 내용이 정말 많네요.
하지만 이제 시작이에요.
우리는 지금 파일을 읽고 쓰는 방법도 아닌, 그냥 저장소 개념만을 학습했어요.
윈도우 설치하면 알아서 따라오는 단지 그 저장소 개념.
def next_chapter(current) :
if current == "HDFS1" :
return "하둡 파일시스템을 직접 구현해보자"
참고자료
문서 : hadoop: The Definitive Guide - Tom white 4th edition
사이트 : https://hadoop.apache.org/docs/r3.3.0/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html
'빅데이터 플랫폼 (Bigdata Platforms) > 아파치 하둡 (Apache Hadoop)' 카테고리의 다른 글
| 하둡 (Apache Hadoop) 4. Zookeeper로 HDFS의 고가용성(High Availability) 달성하기 (0) | 2021.02.22 |
|---|---|
| 하둡 (Apache Hadoop) 3. YARN은 무엇일까? (0) | 2021.02.22 |
| 하둡 (Apache Hadoop) 2. 하둡 완전 분산 모드 구현하기 (1) | 2021.01.07 |