2024. 7. 3. 12:48ㆍ좋은 코드 (Good Code)/좋은 이름 (Good Name)
Directory
간단하게 디렉터리 이야기이다.
요즘 IDE는 검색 기능이 좋아서 이름들을 클릭해주면 어디에 있는 지 알아서 찾아준다.
그러나 대부분의 사람들은 그게 어떤 경로에 있고 어디에 속하는 지는 딱히 관심 없고, 문서나 구현 내용을 보기에 바쁘다.
그렇기에 날이 갈수록 정리하는 습관이 무뎌지고, 어느 순간 난장판이 된 모습을 본 게 적잖아 있었다.
또 필자는 신입 때 querydsl를 보고 감동받아 직접 소스코드를 일일이 열어보고 공부했던 적이 있었는데,
가장 큰 난관은 바로 프로젝트 구조였었다.
여기서 말하는 프로젝트 구조는, 각 디렉터리와 파일들이 역할과 기능에 따라 정리된 형태를 말한다.
types 디렉터리를 보자. (다행히? 아직 그대로이다.)
처음보면 도통 이해하고자 하는 엄두가 안난다.
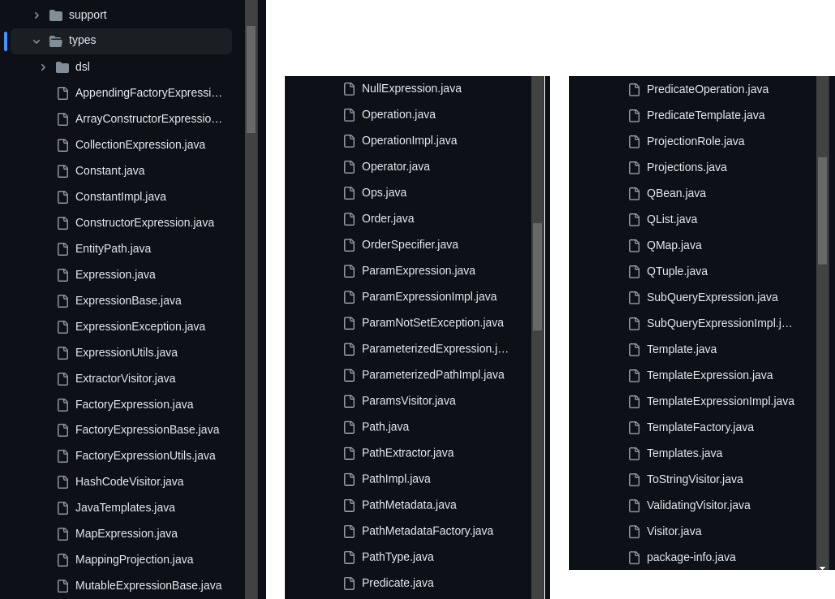
우리는 이 모든 파일이 types 디렉터리에 있다는 걸 인지해야 한다.
QList, QMap, QTuple 또는 Path, Expression 까지 나름 인정한다. 나름 타입이라고 정의했을 것이다.
Operator나 Projection 같은 이름부터 슬슬 냄새가 난다. 이런 게 과연 타입일까...
Template, Visitor 부터는 본인의 통념이 잘못되었음을 깨닫고 다시 처음부터 뜯어야 되었다.
사실 저 파일 이름들은 잘못이 없다.
물론 처음보면 Path나 Template 같은 용어가 어떻게 생겼고, 어떻게 사용되는 지 모르는 게 당연하지만
결국 누가 알려줬든, 스스로 독학하든 모두 이해했다면 저 이름들은 나름 납득이 될 것이다.
문제는 정리가 안되었다는 것이다.
본인 스스로 뭐가 어떻게 생겼는 지 한 눈에 파악할 수 있다는 사실은 관심없다.
누가 보았을 때 이게 뭐야 한다면 어차피 잘못되었다는 것이다.
저기서 Operator가 타입인가요? 물어본다면 필자는 아니라고 대답할 것이다.
package com.querydsl.core.types;
import java.io.Serializable;
/**
* {@code Operator} represents operator symbols.
* <p>Implementations should be enums for automatic instance management.</p>
*
* @author tiwe
*/
public interface Operator extends Serializable {
/**
* Get the unique id for this Operator
*
* @return name
*/
String name();
/**
* Get the result type of the operator
*
* @return type
*/
Class<?> getType();
}
어떤 시각에 따라서, 또는 어떤 설명을 통해 Operator가 타입이라고 정의했다고 한다면,
그 어떤 것이라는 전제 자체가 틀렸다.
그냥 보통 보았을 때 타입이어야 한다. 그 이상은 그냥 저세상 코드인 것이다.
따라서 Operator는 적어도 types 디렉터리가 아니라 operators 디렉터리에 위치해야 한다.
Project Structure
수 많은 기업과 개인은 코드가 어디 디렉터리에 위치해야 하는 지 정의하는 규칙을 가지고 있다.
여기서 벗어나는 이름들을 본다면 분명 눈부터 찡그릴 것이다.
기본적인 규칙은 보통 어떤 프레임워크나 어플리케이션을 사용하느냐에 따라 시작되고 프로젝트 수준까지 내려온다.
이때 사람들은 어떤 이름들을 어떻게 그룹화해야 효율적인지 한 번 쯤 고민해본다.
가령 쇼핑몰 API를 개발한다고 하면, 조회, 결제, 추천 등으로 디렉터리를 만들어서 구분하고
특히 조회 디렉터리 안에서는 의류나 음식 수준으로 또 디렉터리를 만들 것이다.
이렇게 이름들을 그룹화하는 행위는 크게 세 가지 장점이 있다.
- 파일 이름만 보고도 그게 어떤 성격인지, 어떻게 구현될 지 미리 알 수 있다.
- 색인으로써 어떤 코드나 파일을 빠르고 편리하게 찾을 수 있다.
- 어디서 이름을 만들 지 가이드라인을 제공한다.
백엔드 개발자라면 spring-data-jpa는 누구나 써봤을 것이다. 이걸 예시로 들어보겠다.
먼저 밑에 있는 AbstractJpaQuery를 생각해보자.

구현이 어찌될까.
repository/query 아래에 있으니 repository에서 사용하는 query와 밀접한 관련이 있겠다가 첫 번째 생각이고
Abstract니까 Query를 표현하는 데 공통적인 구현만 담겨있을 것이다.
마지막으로 Jpa가 붙었으니 Java Persistence API를 사용하는 쿼리라고 생각한다.
그리고 그 밑의 AbstractStringBasedJpaQuery도 마찬가지로 생각해보면
쿼리 문자열로 표현한 걸 위에서 표현한 쿼리 객체로 해석해줄 것이라고 생각한다.
다음은 객관식 문제이다.
다음 중 JpaRepository가 위치한 디렉터리는 어디일까?

답은 뻔하다.
만약 본인이 CRUD의 기본 연산만 담은 repository를 만든다면 어디에서 개발해야 할까?
여튼 모두 repository 디렉터리를 방문해야 한다.

그리고 CrudRepository 라는 이름은 저 JpaRepository가 위치한 곳에서 만들 것이다.
이렇게 잘 만든 구조는 개발자든 사용자든 모두 이해하기 좋은 상황을 만든다.
필자가 잘 정리된 이름들에게 바라는 건 이 3가지 장점 밖에 없기 때문에, 이를 모두 충족하는 한 많이 만들수록 좋다.
하지만 본인이 만든 이름들이 이 3가지를 모두 충족하지 않는다면,
부디 좋은 이름들로 디렉터리를 만들어서 정리해보길 권한다.
Difference
필자가 생각했을 때 상위 디렉터리와 하위 파일 및 하위 디렉터리의 바람직한 관계는 아래와 같다.
- 하위 파일 및 하위 디렉터리는, 상위 디렉터리와 부모 관계에 있어야 한다.
- 어떤 파일 및 디렉터리를 추가하고자 할 때, 명확하게 상위 디렉터리를 1개 결정할 수 있다.
쉽게 말해 냉장고를 예로 들자면
채소칸, 음료수칸, 얼음칸 같이 냉장고와 부모 관계가 있고
마늘을 넣어두고 싶을 때 채소칸에 넣는 것과 같은 것이다.
왜냐하면 우리는 결코 채소칸을 냉장고 밖에 두거나 마늘을 얼음칸에 두는 멍청한 짓은 하지 않기 때문이다.
2번 조건의 '명확하게 상위 디렉터리를 1개 결정할 수 있다.'를 조금 더 자세하게 설명해보면
과자를 시원하게 먹으려고 냉장고에 넣는다고 해보자.
물론 채소칸, 음료수칸, 얼음칸 모두 넣을 수 있으리라.
이 경우 나중에 과자를 찾을 때 최악의 경우 모든 칸을 뒤져야 할 수도 있다.
이는 바람직하지 않다.
과자칸을 만들거나, 채소칸을 채소-과자칸으로 만들어야 될 것이다.
실제 예시로 들어와서, 만일 본인이 인증 관련 서비스를 개발한다고 해보자.

여기서 MessageVerificationService를 추가하고자 한다면, verfication 디렉터리에 넣으면 된다.
(물론 services 디렉터리를 하나 더 만들어주면 더 명확하다.
하지만 이 예시는 verification이 service 디렉터리에 있기 때문에 필자는 디렉터리를 중복으로 또 만들지 않았다)
MessagePhoneNumberNotFoundException 을 추가하고자 한다면, exceptions 디렉터리에 넣는다.
그러나 만일 이렇게 디렉터리를 만들면 어떨까?

여기서 애매모호함이 발생한다.
address에 넣어도 되고 anonymous에 넣어도 되기 때문이다.
이 경우에 차라리 아래처럼 만드는 것이 낫다.

조금 비틀어서 관계 조건 2개를 모두 충족한 경우를 보자. 바로 exception 디렉터리를 없애는 것이다.

어딘가 어색해보이지만 딱히 문제는 없다.
부모 관계도 맞고, MessageVerificationService 든 MessagePhoneNumberNotFoundException 든
verification 디렉터리에 추가하면 된다.
그러나 계속해서 느끼는 이 어색함은 이전에 설명한 그룹화의 3가지 장점 중 색인 기능을 전혀 하지 못하기 때문이다.
따라서 3가지 장점도 모두 고려한 바탕에서 관계를 해석해야 맞다.
Naming
필자는 디렉터리 이름을 만들 때도, 상위 이름과 하위 파일 및 디렉터리들에 대해 기준을 잡는다.
- 단수 : 상위 및 하위는 서로 목적은 동일하지만 성격이 다르다
- 복수 : 상위 및 하위는 서로 성격은 동일하지만 목적이 다르다
그리고 이 두 가지 기준을 통해 이름을 단수 또는 복수로 정해서 구분하도록 한다.
어렵게 생각할 필요 없다.
만일 본인이 훅(hook) 디렉터리를 만든다고 하면,
하위에는 모두 훅 함수이므로 모두 성격은 같지만 사용하는 목적이 다르므로 복수를 사용한다.
따라서 디렉터리 이름은 hooks 이다.
상품 리스트 페이지 디렉터리를 만든다고 하면,
하위에는 페이지를 구성하는 컴포넌트, 함수, css 처럼 성격이 다르지만,
상품 리스트 페이지를 만드는 목적은 동일하므로 단수를 사용한다.
따라서 디렉터리 이름은 product-list 이다. (또는 product/list 라고도 쓸 수 있겠다)
이 상품 리스트 페이지에 모달(modal)을 만들기 위한 디렉터리가 필요하다면,
하위에 모달들은 성격은 동일하지만 어떻게 쓸 지 목적이 다르다. (예를 들어 상품 가격 편집 목적, 상품 정보 생성 목적 등)
따라서 modals 디렉터리를 만들면 된다.
만약 상품 리스트 페이지에 모달 화면 중 타이틀명을 바꾸고 싶다?
그럼 바로 pages/product-list/modals 로 간다. 이게 바로 정리의 힘이다.
이렇게 단수 복수로 이름을 만드는 건 참 중요하다.
단수인 page라고 한다면 보통 페이지를 만들기 위한 요소들이 모여있는 그룹을 떠올리고,
pages라고 한다면 페이지들이 모여있는 그룹을 떠올리게 해주기 때문이다.
목적과 성격을 이름을 통해 구분할 수 있다는 건 너무 아름다운 일이다.
그렇다면 해당 기준을 벗어나는 경우는 어떻게 할까?
먼저 목적과 성격이 동일하면, 디렉터리를 만들 필요가 없다. 그냥 한 장소에 위치해야 한다.
목적과 성격 모두 다르다면, 디렉터리 깊이를 늘린다. 필자는 보통 목적을 상위에, 성격을 하위에 둔다.
마지막으로 필자가 가장 고민했었던 value object(VO), data transfer object(DTO), enum을 살펴보자.
결론적으로 이 3개를 만들 때 항상 서브 디렉터리를 하나 더 만들고
각각 values, items, enums 처럼 모두 복수로 이름을 짓는다.
모두 다른 목적으로 사용하지만, value, data transfer, enum이라는 같은 성격을 가지고 있기 때문이다.
이를 포괄하는 개념은 더 상위 디렉터리에서 정의하기 때문에, 이렇게만 지어도 문제는 없다.

Summary
아래 3가지 장점을 충족하는 한 그룹화를 할수록 좋다.
- 파일 이름만 보고도 그게 어떤 성격인지, 어떻게 구현될 지 미리 알 수 있다.
- 색인으로써 어떤 코드나 파일을 빠르고 편리하게 찾을 수 있다.
- 어디서 이름을 만들 지 가이드라인을 제공한다.
디렉터리 이름을 아래 기준에 따라 단수 또는 복수로 만든다.
- 단수 : 상위 및 하위는 서로 목적은 동일하지만 성격이 다르다.
- 복수 : 상위 및 하위는 서로 성격은 동일하지만 목적이 다르다.
'좋은 코드 (Good Code) > 좋은 이름 (Good Name)' 카테고리의 다른 글
| 9. 이름은 하나다 (1) | 2024.04.10 |
|---|---|
| 8. 이름은 구조지향적이다. (0) | 2024.04.05 |
| 7. 이름은 바뀌지 않는다. (0) | 2024.03.16 |
| 6. 쓰다가 마는 건 용납하지 못한다 (0) | 2024.03.03 |
| 5. 이름을 만들어주자 (0) | 2024.02.25 |