2021. 1. 29. 15:58ㆍ빅데이터 플랫폼 (Bigdata Platforms)/아파치 하이브 (Apache Hive)
시작하면서
하이브(hive)는 분산 환경에서 대용량 데이터를 읽거나 쓰고 관리하기 위해 개발된 데이터 웨어하우스 소프트웨어입니다.
그런데 대용량 데이터, 즉 빅데이터를 읽고 쓰는 것이 무엇이 그렇게 특별하며 또 웨어하우스는 무엇일까요?
그리고 왜 기업들은 하이브를 고집할까요.
이제 시작하겠습니다.
데이터 웨어하우스의 등장
사람들은 대부분 데이터베이스를 알고 있지만 데이터 웨어하우스는 생소할 것이에요.
참고한 Apache Hive Essentials - Dayong D. 책과 위키에 데이터베이스와 관련한 역사이야기가 나와서, 이해를 쉽게 돕기 위해 한번 공유해보겠습니다.
1960년대
1960년대 이전까지만 해도 기업들은 디스크에 데이터를 읽고 쓰는 것에 그쳤습니다. 사실 디스크라고도 뭐하지만 자기 테이프를 쓰던 시절이었죠. (요즘 사람들은 모를꺼에요. 저도 애기때 역사책에서 본 기억이 있으니까 ^^...)
하지만 이 방식은 어딘가 많이 답답했습니다. 데이터를 공유하기 위해서는 컴퓨터를 뜯어서 주거나 작은 용량의 이동식 디스크로 왔다갔다 조금씩 옮겨야 했으니까 말이죠.
따라서, 기업의 입장에서 대표적으로 비공유성(non-sharable)과 비접근성(non-accessible)에서 큰 비용이 발생합니다. 뭐하나 공유하려고 하면 한나절이 걸리고, 공유했더라도 이게 어디있는 지 설명하는 데 다시 한나절이 걸리기 때문입니다.
따라서 정보에 쉽게 접근하고 공유하는 것은 기업의 생산성과 크게 밀접해있기 때문에, 이러한 요구에 부응하는 연구는 생각보다 빨리 진척되었습니다. 먼저 1962년 옥스퍼드 영어 사전에 데이터베이스(data-base)라는 용어를 '컴퓨터에 저장된 정돈된 데이터 집합으로, 데이터를 보거나 다양한 방법으로 활용할 수 있다'로 정의함으로써, 많은 개발자들이 만들어야할 프로그램의 이름을 붙여 방향성을 찾기 시작했죠.
그리고 가장 먼저 상업화에 뛰어든 것은 1960년대 중반, 코볼(COBOL) 언어를 개발하고 표준화한 CODASYL 그룹에서 공개한 Integrated Data Store(IDS)입니다.

CODASYL 그룹은 키(key)를 정의하고 이를 이용해 각 관계를 만들며, 순차적으로 데이터를 읽을 수 있는 모델을 설계했습니다. 그리고 뒤이어 IBM이 질세라 1966년에 비슷한 구조지만 다른 이름의 Information Management System(IMS)를 개발하였습니다.
지금까지 소개된 소프트웨어의 이름을 보면 알겠지만, 이때까지만 해도 아직 현대의 데이터베이스의 근간이 되는 관계형 데이터베이스의 모델이 표준화되지 않았습니다. 다들 정돈된 데이터 집합을 만들기에 혈안이 되어 있었지, 비공유성(non-sharable)과 비접근성(non-accessible)을 타파하기에는 조금 어려운 점이 있었습니다. 특히 데이터 구조가 linked-list 방식이기 때문에, 참혹한 검색 성능은 여전히 문제를 떠안고 산을 오르는 것과 마찬가지 였습니다.
1970년대
그렇게 1970년대를 맞아 어느 찬란한 2월에, 캘리포니아의 IBM 연구원인 E. F. CODD은 일대의 사건을 하나 만듭니다. 그가 집필한 A Relational Model of Data for Large Shared Data Banks. 이름의 논문은 처음으로 테이블(table)이라는 정형화된 구조를 가지고 기존의 키와 관계를 명료하게 설명함과 동시에 관계 대수(relational calculus)에 기반하여 테이블끼리의 조인(join)을 소개하는 글이었습니다.
위 논문을 시작으로 바클리대의 Eugen W.와 Michael S.는 그 유명한 INGRES 데이터베이스 프로젝트를 시작했고, 쿼리 언어인 QUEL을 개발했으며, IBM도 System R을 시작으로 여러 프로젝트를 진행하면서 현재까지도 알고 있는 Rel을 개발하였습니다.
이제 많은 기업들은 CODD의 논문에 기반해 연구하면서, 데이터베이스 기술은 폭발적으로 진보하였고 이제 그 이름이 Relational DBMS(Data-Base Management System) 또는 SQL(Structured Query Language) DBMS라고 불리기 시작했습니다.
1980년대
RDBMS은 기업에게 공유성과 접근성에 큰 이점을 주었습니다. 누구든 쉽게 데이터베이스에 접속할 수 있을 뿐만 아니라 원하는 정보을 쉽게 검색할 수 있었으니 말이죠. 그러나 1980년대 후반에 접어들면서 사람들은 새로운 욕구가 생깁니다. 사실 그전에도 이야기가 나왔지만, 직접적으로 터진 사건은 1988년에 IBM의 두 연구원 Barry D.와 Paul M. 이 집필한 business data warehouse 논문입니다. 그 이름에도 알 수 있듯 단순히 데이터를 검색해주는 것에서 벗어나, 데이터의 의미 또한 검색해주길 바라는 것이었습니다. 이를 더욱 정확하게 말하면, 사업에 어떤 결정에 대해 도움을 줄 수 있는 정보를 분석하여 제공할 수 있는 decision support system인 데이터 웨어하우스를 요구했던 것입니다.
특히 데이터 웨어하우스는 RDBMS가 가지고 있던 집계나 조인(join)등의 파워풀한 기능과 정합되어 꾸준히 발전하였고, 1990년대에는 각기 다른 분야의 기업에 대해 과거 기록을 변환하고 분석하여 원하는 정보를 추출하도록 개발되었습니다.
21세기
그리고 2000년대를 맞아, 인터넷 시장이 급속도로 커짐으로 소셜 미디어 분석이라던지 웹 마이닝, 데이터 시각화 등 정말 다양한 사업이 기술 발전과 더불어 정점을 찍기 시작했으며, 대망의 2010년으로 접어들면 바로 2006년부터 개발되어 2011년 12월 10일, 분산 파일시스템(Distributed FS)과 맵리듀스(Map Reduce)를 가지고 세상에 나온 하둡이 발표되면서 드디어 기존의 모든 데이터베이스 플랫폼들 뿐만 아니라 데이터 웨어하우스 또한 빅데이터라는 거대한 존재를 업고 그 지평을 더 넓혀갔습니다.
그리고 [페이스북](en.wikipedia.org/wiki/Facebook)에서부터 출발한 하이브는 데이터 웨어하우스 역할을 가지고 하둡의 맵리듀스와 분산 파일시스템에 녹아들며 함께 성장하여 현재 대용량 데이터 웨어하우스로써 큰 존재감을 가지고 있습니다.
그래서 하이브는 무엇인가요?
하이브는 다음과 같은 특징을 가지고 있습니다.
- SQL로 접근할 수 있고, 데이터 추출/변환/적재 (ETL) 구조와 함께 분석까지 가능한 데이터 웨어하우스이다.
- HDFS 및 HBase와 같은 저장소와 연결할 수 있다.
- Apache Tez나 Apache Spark에서 쿼리를 바로 사용할 수 있다.
Built on top of Apache Hadoop™, Hive provides the following features:
- Tools to enable easy access to data via SQL, thus enabling data warehousing tasks such as extract/transform/load (ETL), reporting, and data analysis.
- A mechanism to impose structure on a variety of data formats.
- Access to files stored either directly in Apache HDFS™ or in other data storage systems such as Apache HBase™
- Query execution via Apache Tez™, Apache Spark™, or MapReduce.
- Procedural language with HPL-SQL.
- Sub-second query retrieval via Hive LLAP, Apache YARN and Apache Slider.
또 한 가지는, 데이터가 저장되는 형식(format)이 자유롭다는 것입니다. csv, tsv와 더불어 parguet, orc 등 다양한 데이터 형식 파일을 R/W 할 수 있도록 빌트인 커넥터(built-in connector)도 지원합니다.
There is not a single "Hive format" in which data must be stored. Hive comes with built in connectors for comma and tab-separated values (CSV/TSV) text files, Apache Parquet™, Apache ORC™, and other formats
하이브가 그렇게 좋나요?
최근 하이브의 성능 지표를 알려주는 글이 없었는데, 마침 Sungwoo Park님의 블로그에서 Hive 3.x 에 대한 성능 평가 지표가 있어 공유해드리겠습니다. 꼭! 위 블로그에 방문하셔서 클러스터 사양이나 쿼리 정보 등에 대한 설명을 더욱 풍부하게 들어주세요.
우선 쿼리 수행 시간을 볼까요?

결과를 보면 Impala가 전체 쿼리 수행 시간이 가장 낮음을 알 수 있습니다. 하지만 99개의 쿼리 중 무려 40개나 실패를 경험했네요. 반면에 하이브는 실패를 경험하지 않았는데요, 해당 40개를 논외로 하고 더 빠른 수행시간을 가진 쿼리 개수는 36 vs 23개로 Impala가 13개 더 많았습니다.
실험 결과를 읽어보면 짧은 수행 시간을 가진 쿼리에서는 Impala가 강점을, 긴 수행 시간을 가진 쿼리에서는 Hive가 강점을 가진다는 설명이 있습니다.
- Impala runs faster than Hive on MR3 on short-running queries that take less than 10 seconds.
- For long-running queries, Hive on MR3 runs slightly faster than Impala.
- On the whole, Hive on MR3 is more mature than Impala in that it can handle a more diverse range of queries.
https://mr3.postech.ac.kr/blog/2019/03/22/performance-evaluation-0.6/
마찬가지로 Presto와 Hive를 비교하면, 67개나 Hive가 우세했습니다. 설명에서도 대부분에서 Hive가 더 빠르고, 특히 큰 규모의 데이터에서 훨씬 빠르다고 합니다.
For most queries, Hive on MR3 runs faster than Presto, sometimes an order of magnitude faster.
On the whole, Hive on MR3 and Presto are comparable to each other in their maturity.https://mr3.postech.ac.kr/blog/2019/03/22/performance-evaluation-0.6/
시간이 된다면, 저도 한번 해보아야겠네요.
빅데이터는 무엇일까요?
빅데이터(big data)는 쉽게 말하면, 매우 큰 대용량 데이터를 말합니다. 보통 수 십 ~ 수 백 테라바이트 이상의 데이터 집합을 의미하기 때문에 전통적인 데이터 처리 프로그램으로는 다룰 수 없죠.
Big data is ... or otherwise deal with data sets that are too large or complex to be dealt with by traditional data-processing application software.
(하지만 이렇게만 알고있으면, 진정한 빅데이터 엔지니어라고 할 수 없겠죠?)
빅데이터의 개념은 크게 3가지로, 용량이 매우 크며 다른 형식을 가지는 파일을 빠르게 처리한다는 점에서 크기(volume), 다양성(variety), 속도(velocity)가 있습니다. 하지만 조금 더 들여다보면, 실제 빅데이터 마이닝에 따져야할 요소는 5가지가 더 있습니다.
모든 요소를 한번 정리해보면,
- 크기(Volume) : 시간 초(second)내에 생성되는 데이터 크기입니다.
- 속도(Velocity) : 데이터의 생성, 저장, 분석, 이동(move)되는 속도입니다.
- 다양성(Variety) : 데이터 형식(format)이 다른(.txt나 .csv과 같이) 파일을 말하거나 광의적으로는 이메일이라던지 사진, 동영상과 같은 정보의 다양성을 말합니다.
- 진실성(Veracity) : 데이터는 오류나 결함이 없으며 수집 목적에 부합하는 내용을 가집니다.
- 가변성(Variability) : 동일한 데이터도 활용 목적에 따라 다른 의미를 가집니다.
- 휘발성(Volatility) : 데이터가 지속되는 시간을 의미합니다.
- 시각화(Visualization) : 데이터를 이해하기 쉽게 만드는 것입니다.
- 가치(Value) : 데이터를 분석하여 의미를 도출하는 것입니다.
In summary, big data is not just about lots of data, it is a practice to discover new insight
from existing data and guide the analysis of new data.Apache Hive Essentials - Dayong D.
하이브의 구조
하이브 위키 사이트에서는 2015년 11월에 업로드된 하이브 아키텍쳐를 소개하고 있습니다. 날짜가 너무 오래되어서 혹여나 바뀌지 않았을까 다방면으로 찾아보았는데, 대부분 동일하거나 더욱 뭉퉁그려 표현하고 있었네요.
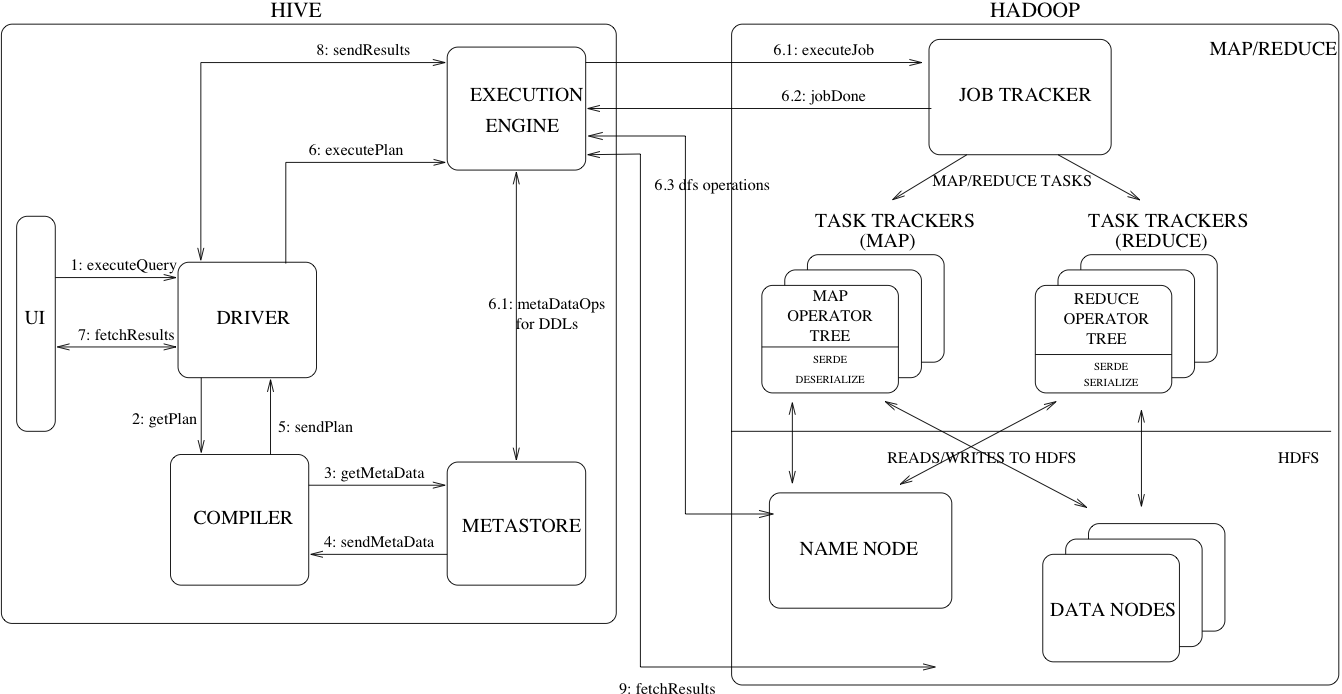
위 그림은 하이브가 쿼리를 수행하는 과정을 담고 있습니다. 보면 알겠지만 서버는 드라이버(driver), 컴파일러(compiler), 메타스토어(metastore), 실행 엔진(execution engine)으로 구성되어 있습니다. 그리고 실행 엔진은 맵리듀스 및 데이터 I/O를 위해 하둡 자원과 연결되어 있죠.
우선 위 구성요소를 정리해보면,
- Driver : The component which receives the queries. This component implements the notion of session handles and provides execute and fetch APIs modeled on JDBC or ODBC interfaces.
- Compiler : The component that parses the query, does semantic analysis on the different query blocks and query expressions and eventually generates an execution plan with the help of the table and partition metadata looked up from the metastore.
- Metastore : The component that stores all the structure information of the various tables and partitions in the warehouse including column and column type information, the serializers and deserializers necessary to read and write data and the corresponding HDFS files where the data is stored.
- Execution Engine : The component which executes the execution plan created by the compiler. The plan is a DAG of stages. The execution engine manages the dependencies between these different stages of the plan and executes these stages on the appropriate system components.
입니다.
사실 위 설명만 보고는 어딘가 빈 기분이 들어, 전체 과정을 직접 머리로 그리고 나서야 이해가 쉬웠습니다. (ㅎㅎ)
1. 쿼리 전달

Spark SQL과 같은 사용자 인터페이스에서 쿼리문을 작성해서 실행하면, 해당 쿼리는 JDBC 또는 ODBC를 통해 드라이버에게 전송됩니다. 드라이버는 해당 쿼리를 받고, 맵리듀스를 수행하기 위해 실행 계획을 컴파일러에게 요구합니다.
2. 메타 정보 얻기

메타스토어는 테이블이 HDFS에서 어디에 존재하는지, 그리고 해당 테이블에 대한 스키마 정보와 파티션 정보 등을 알고 있습니다. 따라서 컴파일러는 실행 계획을 만들기 앞서, 메타스토어에서 위 정보를 통해 어디서 테이블을 접근하고 또 쿼리문에 있는 데이터 타입이 올바른 지 등을 확인합니다.
3. 실행 계획 전달하기

컴파일러는 비순환 유향 그래프로 어떻게 맵리듀스를 수행해야 하는 지 알려줍니다. 예를 들어 두 테이블 간 조건부 조인(join)의 경우, 두 테이블에서 각각 조건에 대해 맵리듀스를 수행하고 그 결과를 다시 맵리듀스로 합쳐야 하는 상황이 있기 때문에 머리 속으로 그래프를 그려보면 쉽게 이해할 수 있습니다. 드라이버는 컴파일러로부터 맵리듀스 실행 계획을 받아 실행 엔진에게 전달합니다.
4. 맵리듀스 하기

실행 엔진은 바로 하둡에 접속해 맵리듀스 작업을 요청합니다. 본 그림은 YARN으로 하둡 완전 분산 모드를 구현했을 때 처리되는 과정을 나타내며, 맵리듀스가 종료되면 실행 결과를 다시 실행 엔진에게 제공합니다.
5. 결과 전달하기

마지막으로 실행 엔진은 다시 드라이버에게 결과를 전달하고, 드라이버는 Spark가 읽을 수 있는 형식으로 변환(fetch)하여 전달합니다. 따라서 Spark 사용자는 결과를 데이터프레임으로 볼 수 있겠죠?
끝내면서
이제 하이브에 대한 개념이 조금은 잡혔나요?
아직 DDL이나 데이터 모델, 그리고 구성 요소들의 세부적인 설명을 하지 않았어요.
이는 추후 직접 하이브와 메타스토어를 구현하면서 설명하도록 하겠습니다.