2021. 1. 12. 09:50ㆍ빅데이터 플랫폼 (Bigdata Platforms)/아파치 주키퍼 (Apache Zookeeper)
시작하면서
분산(distributed) 환경에서 동작하는 시스템은 어떻게 관리하고 감독해야 될까요?
가령 A, B, C 라는 컴퓨터가 동일한 잡을 수행하다, C가 말썽을 일으켰다고 할게요. 그럼 우리는 C에 방문해서 무엇이 문제인지 알아낼 수 있겠죠. 하지만 A0, A1, ..., A99 까지 100대의 컴퓨터가 있을 때는, 일일이 방문해가며 원인을 찾을 수 있을까요?
정답은 찾을 수 있지만 고통스럽다 입니다.
매번 할당되는 컴퓨터를 파악하는 것도 문제지만 일일이 어떻게 감독하고 고쳐나갈 지도 너무 힘들 것입니다.
즉, 우리는 실패에 대해 신속하고 정확하면서 범용성을 지닌 관리자 및 감독자가 필요합니다. 당연히 이들 또한 스스로의 결함에 대해 고칠 수단이 강력해야겠죠. 그리고 이러한 기능은 비단 결함 수리에 그치지 않습니다.
이제 시작할게요.
주키퍼란?
주키퍼는 분산 코디네이션 서비스로써 분산된 어플리케이션에 대한 그룹 또는 개별적으로 설정 정보를 유지하고 동기화를 수행하며 개개인의 위치 정보도 제공(naming)합니다.
ZooKeeper is a distributed, open-source coordination service for distributed applications. It exposes a simple set of primitives that distributed applications can build upon to implement higher level services for synchronization, configuration maintenance, and groups and naming.
이때 코디네이션 서비스(coordination service)라는 용어에 대해 궁금증을 가졌었는데, 쉽게 말하면 사용자들이 어떤 동작을 할 때 충돌나지 않도록 조정하는 서비스였습니다.
In general, coordination between participants will require sequencing of actions (an action at one participant has to wait for the occurrence of some actions at other participants), resolving conlicts between actions (two or more participants may be ready to perform some actions but only one can be allowed to do so) or synchronizing actions (two participants are blocked until both are ready to perform their respective actions).
A Coordination Service for Distributed Applications - Gurdip S., Arvind G.
Coordination services are notoriously hard to get right. They are especially prone to errors such as race conditions and deadlock.
이러한 주키퍼에 다음과 같이 4개의 주요한 설계 목적이 있습니다.
- 간단해야된다.
- 복제본을 가진다.
- 정렬할 수 있다.
- 빠르다.
이제 이에 대해서 설명해보겠습니다.
1. 간단해야 된다.
주키퍼는 기본 파일시스템 구조를 가지고 있습니다. 이는 다음 그림처럼 트리 형태로 표현할 수 있는데요.

원 안에 있는 것이 파일 또는 디렉토리 이름이라면 경로/이름을 위와 같이 정의할 수 있습니다. 보시다시피 어떤 노드를 접근하기 위해서는 상위 노드로부터 접근해야 하므로 계층적 네임스페이스(hierachical namespace)라고 할 수 있습니다.
그리고 주키퍼는 각 노드를 제트노드(znode)라고 부릅니다. 제트노드는 메모리 내에 상주하므로 높은 처리량과 적은 지연 시간을 가질 수 있습니다.
The namespace provided by ZooKeeper is much like that of a standard file system. A name is a sequence of path elements separated by a slash (/). Every node in ZooKeeper's namespace is identified by a path.
2. 복제본을 가진다.
주키퍼는 서버-클라이언트 시스템 구조를 가지고 있습니다.

먼저 여러 개의 주키퍼 서버를 그룹으로 묶습니다. 이 그룹을 주키퍼 앙상블(ensemble)이라고 부르는데, 클라이언트는 주키퍼 앙상블에게 데이터를 보내고, 앙상블은 해당 데이터를 복제하여 내부에 있는 서버들에게 전달합니다.
따라서 주키퍼 앙상블 내 서버들은 당연히 서로 연결되어 있어야하며, 데이터베이스와 트랜잭션(transaction) 로그를 참조하여 앞서 설명했던 메모리 내 제트노드 구조를 만듭니다(모두 read 는 할 수 있다는 말이죠). 하지만 실질적으로 클라이언트의 요청을 받아 데이터베이스에 작성(write)하는 노드는 단 한 개입니다. 해당 역할을 받은 서버를 리더(leader)라고 하고 나머지를 팔로워(follower)라고 부르는 데, 말 그대로 리더가 데이터베이스를 변경하면 팔로워는 이에 따라 동기화(syncing)를 수행하거나 리더가 없어지면 다른 팔로워에서 리더를 새롭게 선출합니다.
따라서 정리하면, 클라이언트의 요청은 앙상블 내 어떤 서버나 받을 수 있으나 쓰기(write)의 경우 해당 요청을 리더에게 전달하여 처리하게 하고, 그 결과를 받아 다시 클라이언트에게 응답하는 것입니다.
Every ZooKeeper server services clients. Clients connect to exactly one server to submit requests. Read requests are serviced from the local replica of each server database. Requests that change the state of the service, write requests, are processed by an agreement protocol. As part of the agreement protocol all write requests from clients are forwarded to a single server, called the leader. The rest of the ZooKeeper servers, called followers, receive message proposals from the leader and agree upon message delivery. The messaging layer takes care of replacing leaders on failures and syncing followers with leaders.
특히 주키퍼는 쿼럼(quorum) 모드로 동작합니다.(standalone은 생략)
만약 모든 서버에게 데이터를 전달할 경우, 클라이언트는 모든 서버가 정상적으로 데이터를 받아 처리할 때까지 기다려야되는 치명적인 지연 시간이 존재합니다. 이를 위해 쿼럼을 이용하는 데, 클라이언트의 데이터를 안전하게 처리한 서버의 수가 쿼럼의 크기가 되면 클라이언트에게 정상 처리되었다는 신호를 보내고, 나머지 서버는 클라이언트의 데이터를 처리할 필요가 없이 다시 대기 상태가 되도록 합니다.
In public administration, a quorum is the minimum number of legislators required to be present for a vote. In ZooKeeper, it is the minimum number of servers that have to be running and available in order for ZooKeeper to work. This number is also the minimum number of servers that have to store a client’s data before telling the client it is safely stored.
ZooKeeper - Flavio J., Benjamin R., 24p
따라서 당연히 쿼럼의 크기를 적절히 구하는 것이 매우 중요합니다. 너무 많으면 지연시간이 더 크고, 너무 적으면 장치 결함에 대한 신뢰성을 잃어버리기 때문이죠. 하지만 쿼럼의 크기는 다음 이유에서 무조건 과반수를 넘겨야 됩니다.

위 상황은 주키퍼 서버가 5개이고, 쿼럼의 크기가 2개일 때를 가정했습니다.
/z 이름의 제트노드를 만들라는 클라이언트 요청에 주키퍼 서버 Server1과 Server2에 해당 요청이 잘 복제되었다고 했을 때, 두 서버는 클라이언트에게 /z 가 생성되었다는 메시지를 보내야 합니다. 하지만 여기서 갑자기 지연시간이 길어졌다고 합니다. 이때 주키퍼 앙상블은 다음 클라이언트의 요청을 받는데, 주키퍼 서버가 3개 남았으므로 다른 2개의 서버가 해당 요청을 받아 처리할 수 있습니다. 만약 Server3, Server4가 이를 처리한다고 가정했을 때, 하지만 아직 이전 요청에 대한 응답이 없으므로 네임스페이스에는 /z 노드가 없다는 에러를 클라이언트에게 전달할 것입니다.
그럼 만약 쿼럼의 크기가 3개일 때는 어떻게 될까요?
이전 요청을 처리할 서버가 3개이므로 2개가 남아, 쿼럼을 형성할 수 없기 때문에 /z 가 생성되고 나서야 /z/app 을 생성할 것입니다. 또한 만약 앙상블 내의 서버 중 1개가 고장이 났을 때, 나머지 4개의 서버 중 3개를 여전히 쿼럼으로 선출할 수 있습니다.
이런 원리로 생각하면 최대 2개의 서버에 대한 결함을 감내(tolerate)할 수 있겠죠?
Quorums must guarantee that, regardless of delays and crashes in the system, any update request the service positively acknowledges will persist until another request supersedes it.
ZooKeeper - Flavio J., Benjamin R., 24p
아래 사진은 주키퍼 사이트에서 소개한 신뢰성(reliability)에 관한 그래프입니다.
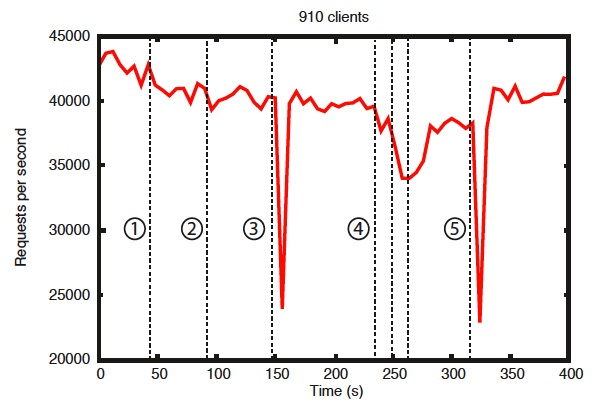
7대의 장치에서 주키퍼를 실행했을 때, 각 번호 순으로 장치 결함을 의도적으로 만들었는데요. ①와 ②의 경우 팔로워가 결함이 생겼을 때, 다른 팔로워가 쿼럼이 될 수 있으므로 여전히 높은 처리량으로 진행되는 모습을 보여주고, ③의 경우 결함이 있는 장치가 리더임을 알 수 있는 데, 200ms 내에 다른 팔로워들로부터 리더를 선출하여 기존 처리량을 복구할 수 있다고 합니다.
3. 정렬할 수 있다.
주키퍼는 요청을 처리한 시간대로 기록하고 정렬합니다 당연히 이는 동기화를 어디부터 시작해야 되는 지에 대한 정보를 제공해주거나 트랜잭션을 추척할 수 있는 등 매우 유용하게 사용할 수 있죠.
For example, if a client creates a sequential znode with the path /tasks/ task-, ZooKeeper assigns a sequence number, say 1, and appends it to the path. The path of the znode becomes /tasks/task-1. Sequential znodes provide an easy way to create znodes with unique names. They also provide a way to easily see the creation
order of znodes.ZooKeeper - Flavio J., Benjamin R., 20p
4. 빠르다.
사실 빠르다는 것은 상대적인 의미이기 때문에 그 자체로는 의미가 없습니다.
따라서 이를 적절히 설명하기 위해서는
- 얼마나 빠른가?
- 왜 빠른가?
에 대한 설명이 되어야 될 것 같습니다.
먼저 아래는 주키퍼 사이트에서 소개한 성능 그래프입니다.
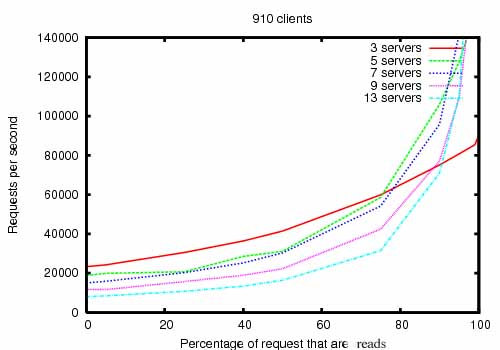
위 그래프에서 3, 5, 7, 9, 13는 앙상블 내 서버의 개수 단위를 의미하며 총 30여개의 주키퍼 서버가 사용되었다고 합니다. 가장 느린 write 연산이 100%일 때 초당 평균 약 18,000 개의 요청을 처리하는 것과 read 비중에 따라 지수적으로 증가하여 read 연산이 100%에 다다를 때 초당 140,000 개까지 처리할 수 있음을 알 수 있습니다.
... running on servers with dual 2Ghz Xeon and two SATA 15K RPM drives. One drive was used as a dedicated ZooKeeper log device. The snapshots were written to the OS drive. Write requests were 1K writes and the reads were 1K reads.
https://zookeeper.apache.org/doc/r3.6.2/zookeeperOver.html#zkPerfRW
주키퍼가 어느 정도 빠르다는 것은 감이 옵니다. 하지만 가장 중요한 '왜'를 알아야 우리가 주키퍼를 사용해야할 가장 중요한 근거가 되겠죠? 이에 대한 설명은 다음 챕터에서 진행하도록 하겠습니다.
왜 빠른가?
클라이언트는 기본적으로 서버에 원격으로 접근합니다. 따라서 당연히 네트워크 지연 시간이 존재하겠죠? 만일 클라이언트가 어떤 제트노드가 추가되었을 때 새로운 작업을 하고 싶다고 가정해볼게요. 그럼 어떻게 이를 구현해야될까요?

위 그림은 클라이언트 트리가 /tasks 내에 제트노드가 있는 지 확인하는 두 가지 방법을 소개하고 있습니다. 그 중 첫 번째 방법은 계속 서버에게 질의를 하는 방법인데요, task- 제트노드가 언제 추가될 지 모르는 상황에서 이 방법은 재앙(disaster)급으로 지연시간이 매우 증가할 것입니다. 두 번째 방법은 알림을 받는 방법입니다. 1번 이후에 주키퍼 서버로부터 알림이 올 때까지 대기 상태로 있는 모습을 볼 수 있는데요, 이는 계속 질의를 하는 것보다 더 효율적입니다. 따라서 해당 방법을 감시&알림(Watches&Notification)이라고 부릅니다.
그렇다면 감시 전에 다른 클라이언트가 새로운 노드를 추가하면 어떻게 될까요?

감시에 대한 응답으로 주키퍼 서버가 현재 /tasks 내 제트노드를 알려주기 때문에 문제가 없습니다!
Clients register with ZooKeeper to receive notifications of changes to znodes. Registering to receive a notification for a given znode consists of setting a watch.
ZooKeeper - Flavio J., Benjamin R., 21p
데이터 일관성은 어떻게 해결하나요?
조금 더 심층적으로 파고들겠습니다.
사실 위에서 감시&알림을 설명할 때 편의상 산타의 동작에 대한 응답을 기술하지 않았습니다.
하지만 제트노드 안의 내용을 변경하면 주키퍼는 해당 제트노드에 대한 버전(version)을 이전보다 1 증가시킵니다. 예를 들어 산타의 요청으로 인해 /tasks의 버전이 원래 0이었다면 1로 변경된 것과 마찬가지입니다. 그리고 산타에게 바뀐 버전 정보를 알려주죠.
따라서 어떤 제트노드에 대해 현재 버전을 알고 있는 클라이언트만이 해당 제트노드의 내용을 변경할 수 있습니다. 따라서 제트노드를 읽고 쓰는 연산이 원자적(atomically)이므로 데이터 일관성이 보장됩니다. 이는 향후 직접 주키퍼를 사용하면서 더 자세히 설명하도록 하겠습니다.
끝내면서
지금까지 주키퍼에 대한 개요 설명이었습니다.
당연히 아직은 주키퍼가 막연하게 느껴질지도 모르겠습니다. 하지만 다음 포스팅에서 실제로 주키퍼를 사용해봄으로 더욱 많은 공부가 되었으면 좋겠습니다.
'빅데이터 플랫폼 (Bigdata Platforms) > 아파치 주키퍼 (Apache Zookeeper)' 카테고리의 다른 글
| 주키퍼 (Apache Zookeepr) 2. 주키퍼 클러스터 설치 (0) | 2021.01.18 |
|---|